This chapter illustrates the application of the method using one example of real-world datasets. We have trained a GAMSEL model on a binary variable to estimate the underlying event probabilities using available covariates. We therefore consider the Beta prior as the “true probability distribution”. Here, we train a certain XGBoost model (the hyperparameters are selected randomly on the validation sample), and predict it to train/validation/calibration/test sets. Recalibration models are fitted on the calibration sets and then applied to the test to calculate performance, dispersion and calibration metrics.
Code Availability
The functions for data preprocessing, model estimation, and Beta distribution fitting are stored in ../scripts/functions/real-data.R and will be used in subsequent chapters.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Attaching package: 'xgboost'
The following object is masked from 'package:dplyr':
slice
library(pbapply)library(parallel)library(gam)
Loading required package: splines
Loading required package: foreach
Attaching package: 'foreach'
The following objects are masked from 'package:purrr':
accumulate, when
Loaded gam 1.22-5
library(betacal)library(gamsel)
Loaded gamsel 1.8-5
library(locfit)
locfit 1.5-9.10 2024-06-24
Attaching package: 'locfit'
The following object is masked from 'package:purrr':
none
# Colours for train/validation/calibration/testcolour_samples <-c("Train"="#0072B2","Validation"="#009E73","Calibration"="#CC79A7","Test"="#D55E00")colour_recalib <-c("None"="#88CCEE","Platt"="#44AA99","Isotonic"="#882255","Beta"="darkgoldenrod","Locfit"="firebrick3")# Functionssource("../scripts/functions/real-data.R")source("../scripts/functions/metrics.R")
definition of the theme_paper() function (for ggplot2 graphs)
To train the models, we rely on the {xgboost} R package.
library(xgboost)
8.1.2 Recalibration
Here, we define a function to recalibrate predicted scores using either Platt scaling or isotonic regression. The recalibration algorithm is first trained on the calibration set and then applied to both the calibration and test sets.
#' Recalibrates scores using a calibration#' #' @param obs_calib vector of observed events in the calibration set#' @param scores_calib vector of predicted probabilities in the calibration set#' @param obs_test vector of observed events in the test set#' @param scores_test vector of predicted probabilities in the test set#' @param method recalibration method (`"platt"` for Platt scaling, #' `"isotonic"` for isotonic regression, `"beta"` for Beta calibration, #' `"locfit"` for local regression techniques)#' @returns list of two elements: recalibrated scores on the calibration set,#' recalibrated scores on the test setrecalibrate <-function(obs_calib, obs_test, pred_calib, pred_test,method =c("platt", "isotonic", "beta", "locfit")) { data_calib <-tibble(d = obs_calib, scores = pred_calib) data_test <-tibble(d = obs_test, scores = pred_test)if (method =="platt") { lr <-glm(d ~ scores, family =binomial(link ='logit'), data = data_calib) score_c_calib <-predict(lr, newdata = data_calib, type ="response") score_c_test <-predict(lr, newdata = data_test, type ="response") } elseif (method =="isotonic") { iso <-isoreg(x = data_calib$scores, y = data_calib$d) fit_iso <-as.stepfun(iso) score_c_calib <-fit_iso(data_calib$scores) score_c_test <-fit_iso(data_test$scores) } elseif (method =="beta") { fit_beta <-beta_calibration(data_calib$scores, data_calib$d, parameters ="abm") score_c_calib <-beta_predict(data_calib$scores, fit_beta) score_c_test <-beta_predict(data_test$scores, fit_beta) } elseif (method =="locfit") { noise_scores <- data_calib$scores +rnorm(nrow(data_calib), 0, 0.01) noise_data_calib <- data_calib %>%mutate(scores = noise_scores) locfit_reg <-locfit(formula = d ~lp(scores, nn =0.15, deg =0),kern ="rect", maxk =200, data = noise_data_calib ) score_c_calib <-predict(locfit_reg, newdata = data_calib) score_c_test <-predict(locfit_reg, newdata = data_test) } else {stop("Unrecognized method: platt or isotonic only") }# Format results in tibbles:# For calibration set tb_score_c_calib <-tibble(d = obs_calib,p_u = pred_calib,p_c = score_c_calib )# For test set tb_score_c_test <-tibble(d = obs_test,p_u = pred_test,p_c = score_c_test )list(tb_score_c_calib = tb_score_c_calib,tb_score_c_test = tb_score_c_test )}
8.1.3 Dispersion Metrics
We modify our dispersion_metrics() function to replace the vector of simulated true probabilities with the parameters of a Beta distribution. This adjustment allows us to compute the divergence between the model-estimated scores and the specified Beta distribution.
Function dispersion_metrics_beta()
#' Computes the dispersion and divergence metrics for a vector of scores and#' a Beta distribution#'#' @param shape_1 first parameter of the beta distribution#' @param shape_2 second parameter of the beta distribution#' @param scores predicted scores#'#' @returns#' \itemize{#' \item \code{inter_quantile_25_75}: Difference of inter-quantile between 25% and 75%#' \item \code{inter_quantile_10_90}: Difference of inter-quantile between 10% and 90%#' \item \code{KL_10_true_probas}: KL of of predicted probabilities w.r. to true probabilities with 10 bins#' \item \code{KL_10_scores}: KL of of true probabilities w.r. to predicted probabilities with 10 bins#' \item \code{KL_20_true_probas}: KL of of predicted probabilities w.r. to true probabilities with 20 bins#' \item \code{KL_20_scores}: KL of of true probabilities w.r. to predicted probabilities with 20 bins#' \item \code{ind_cov}: Difference between the variance of true probabilities and the covariance between true probabilities and predicted scores#' }dispersion_metrics_beta <-function(shape_1 =1, shape_2 =1, scores){# Inter-quantiles inter_q_80 <-diff(quantile(scores, c(.9, .1))) /diff(qbeta(c(.9, .1), shape_1, shape_2)) inter_q_50 <-diff(quantile(scores, c(.75,.25))) /diff(qbeta(c(.75,.25), shape_1, shape_2))# KL divergences m <-10# Number of bins h_phat <-hist(scores, breaks =seq(0, 1, length = m +1), plot =FALSE) h_p <-list(breaks = h_phat$breaks, mids = h_phat$mids) h_p$density =diff(pbeta(h_p$breaks, shape_1, shape_2)) h_p$counts = h_p$density*length(scores)# Densities h1 <-rbind(h_phat$density / m, h_p$density / m) # Reference : true probabilities h2 <-rbind(h_p$density / m, h_phat$density / m) # Reference : predicted scores KL_10_true_probas <-distance( h1, method ="kullback-leibler", unit ="log2", mute.message =TRUE) KL_10_scores <-distance( h2, method ="kullback-leibler", unit ="log2", mute.message =TRUE) m <-20# Number of bins h_phat <-hist(scores, breaks =seq(0, 1, length = m +1), plot =FALSE) h_p <-list(breaks = h_phat$breaks, mids = h_phat$mids) h_p$density =diff(pbeta(h_p$breaks, shape_1, shape_2)) h_p$counts = h_p$density *length(scores)# Densities h1 <-rbind(h_phat$density / m, h_p$density) # Reference : true probabilities h2 <-rbind(h_p$density, h_phat$density / m) # Reference : predicted scores KL_20_true_probas <-distance( h1, method ="kullback-leibler", unit ="log2", mute.message =TRUE) KL_20_scores <-distance( h2, method ="kullback-leibler", unit ="log2", mute.message =TRUE)# Indicator of the difference between variance and covariance var_p <- shape_1 * shape_2 / ((shape_1 + shape_2)^2* (shape_1 + shape_2 +1)) cov_p_phat <-cov(qbeta(rank(scores, ties.method ="average") / (1+length(scores)), shape_1, shape_2), scores ) ind_cov <-abs(cov_p_phat - var_p)# Collection dispersion_metrics <-tibble("inter_quantile_25_75"=as.numeric(inter_q_50),"inter_quantile_10_90"=as.numeric(inter_q_80),"KL_10_true_probas"=as.numeric(KL_10_true_probas),"KL_10_scores"=as.numeric(KL_10_scores),"KL_20_true_probas"=as.numeric(KL_20_true_probas),"KL_20_scores"=as.numeric(KL_20_scores),"ind_cov"= ind_cov ) dispersion_metrics}disp_metrics_dataset <-function(prior, scores) {# GAMSEL prior shape_1 <- prior$mle_gamsel$estimate["shape1"] shape_2 <- prior$mle_gamsel$estimate["shape2"]# Divergence metrics dist_prior_gamsel <-dispersion_metrics_beta(shape_1 = shape_1, shape_2 = shape_2, scores = scores ) dist_prior_gamsel |>mutate(prior ="gamsel", shape_1 = shape_1, shape_2 = shape_2 )}
We train XGB models on the dataset “spambase”, varying the maximum tree depth (with values of 2, 4, or 6) and the number of boosting iterations (ranging from 2 to 500). At each iteration, we compute metrics based on scores from both the train, calibration, validation and test samples, as well as the recalibrated scores.
This function allows us to calculate the performance, dispersion and calibration metrics on all sets of the dataset at a given iteration for a single XGBoost algorithm:
We then define a function to predict a XGBoost algorithm on train, validation, calibration and test samples given an xgboost object (fit). We are able to obtain the predicted scores at a specified iteration during the training of the algorithm:
Function predict_score_iter()
#' Predicts the scores at a given iteration of the XGB model#'#' @param fit_xgb estimated XGB model#' @param tb_train_xgb train set#' @param tb_valid_xgb validation set#' @param tb_test_xgb test set#' @param ind index of the grid search#' @param nb_iter boosting iteration to consider#'#' @returns A list with three elements: `scores_train`, `scores_valid`, and#' `scores_train` which contain the estimated scores on the train and on the #' test score, resp.predict_score_iter <-function(fit_xgb, tb_train_xgb, tb_valid_xgb, tb_calib_xgb, tb_test_xgb, nb_iter) {## Predicted scores---- scores_train <-predict(fit_xgb, tb_train_xgb, iterationrange =c(1, nb_iter)) scores_valid <-predict(fit_xgb, tb_valid_xgb, iterationrange =c(1, nb_iter)) scores_calib <-predict(fit_xgb, tb_calib_xgb, iterationrange =c(1, nb_iter)) scores_test <-predict(fit_xgb, tb_test_xgb, iterationrange =c(1, nb_iter))list(scores_train = scores_train,scores_valid = scores_valid,scores_calib = scores_calib,scores_test = scores_test )}
This function calculates the different metrics on train, validation, calibration and test samples for a given XGBoost algorithm at all iterations:
Function simul_xgb_helper()
#' Fit an XGB and returns metrics based on scores. The divergence metrics are#' obtained using the prior distributions.#'#' @param data_train train set#' @param data_valid validation set#' @param data_calib calibration set#' @param data_test test set#' @param prior_train train prior scores#' @param prior_valid validation prior scores#' @param prior_calib calibration prior scores#' @param prior_test test prior scores#' @param target_name name of the target variable#' @param parms tibble with hyperparameters for the current estimation#' @param prior prior obtained with `get_beta_fit()`#'#' @returns A list with 4 elements:#' - `tb_metrics`: performance / calibration metrics#' - `tb_disp_metrics`: disp and div metrics#' - `tb_prop_scores`: table with P(q1 < score < q2)#' - `scores_hist`: histogram of scoressimul_xgb_helper <-function(data_train, data_valid, data_calib, data_test, prior_train, prior_valid, prior_calib, prior_test, target_name, params, prior) {## Format data for xgboost---- tb_train_xgb <-xgb.DMatrix(data = data_train |> dplyr::select(-!!target_name) |>as.matrix(),label = data_train |> dplyr::pull(!!target_name) |>as.matrix() ) tb_valid_xgb <-xgb.DMatrix(data = data_valid |> dplyr::select(-!!target_name) |>as.matrix(),label = data_valid |> dplyr::pull(!!target_name) |>as.matrix() ) tb_calib_xgb <-xgb.DMatrix(data = data_calib |> dplyr::select(-!!target_name) |>as.matrix(),label = data_calib |> dplyr::pull(!!target_name) |>as.matrix() ) tb_test_xgb <-xgb.DMatrix(data = data_test |> dplyr::select(-!!target_name) |>as.matrix(),label = data_test |> dplyr::pull(!!target_name) |>as.matrix() )# Parameters for the algorithm param <-list(max_depth = params$max_depth, #Note: root node is indexed 0eta = params$eta,nthread =1,objective ="binary:logistic",eval_metric ="auc" ) watchlist <-list(train = tb_train_xgb, eval = tb_valid_xgb)## Estimation---- fit_xgb <-xgb.train( param, tb_train_xgb,nrounds = params$nb_iter_total, watchlist,verbose =0 )# First, we estimate the scores at each boosting iteration# As the xgb.Dmatrix objects cannot be easily serialised, we first estimate# these scores in a classical way, without parallelism... scores_iter <-vector(mode ="list", length = params$nb_iter_total)for (i_iter in1:params$nb_iter_total) { scores_iter[[i_iter]] <-predict_score_iter(fit_xgb = fit_xgb,tb_train_xgb = tb_train_xgb,tb_valid_xgb = tb_valid_xgb,tb_calib_xgb = tb_calib_xgb,tb_test_xgb = tb_test_xgb,nb_iter = i_iter) }# Then, to compute the metrics, as it is a bit slower, we can use parallelism ncl <-detectCores() -1 (cl <-makeCluster(ncl))clusterEvalQ(cl, {library(tidyverse)library(locfit)library(philentropy)library(betacal) }) |>invisible()clusterExport(cl, c("scores_iter", "prior", "data_train", "data_valid", "data_calib", "data_test", "prior_train", "prior_valid", "prior_calib", "prior_test", "params", "target_name" ), envir =environment())clusterExport(cl, c("get_metrics_xgb_iter","brier_score","compute_metrics","disp_metrics_dataset", "dispersion_metrics_beta","recalibrate", "prop_btw_quantiles", "calculate_log_loss","calculate_kl", "decomposition_metrics", "kullback_leibler" )) metrics_iter <- pbapply::pblapply(X =seq_len(params$nb_iter_total),FUN =function(i_iter) {get_metrics_xgb_iter(scores = scores_iter[[i_iter]],prior = prior,data_train = data_train,data_valid = data_valid,data_calib = data_calib,data_test = data_test,prior_train = prior_train,prior_valid = prior_valid,prior_calib = prior_calib,prior_test = prior_test,target_name = target_name,ind = params$ind,nb_iter = i_iter,params = params ) },cl = cl )stopCluster(cl)# Merge tibbles from each iteration into a single one tb_metrics <-map(metrics_iter, "tb_metrics") |>list_rbind() tb_prop_scores <-map(metrics_iter, "tb_prop_scores") |>list_rbind() tb_decomposition_scores <-map(metrics_iter, "tb_decomposition") |>list_rbind() scores_hist <-map(metrics_iter, "scores_hist")list(tb_metrics = tb_metrics,tb_prop_scores = tb_prop_scores,tb_decomposition_scores = tb_decomposition_scores,scores_hist = scores_hist )}
8.2 Import Data and Prior
We load the dataset “spambase” and the associated Beta prior on both train and test sets.
The different configurations are reported in Table 9.1.
DT::datatable(grid)
Table 8.1: Grid Search Values
We define a function, simul_xgb_real() to train the model on a dataset for all different values of the hyperparameters of the grid (and for all iterations of each algorithm, defined by a row in the grid).
Function simul_xgb_real()
#' Train an XGB on a dataset for a binary task for various#' hyperparameters and computes metrics based on scores and on a set of prior#' distributions of the underlying probability#'#' @param data dataset#' @param target_name name of the target variable#' @param prior prior obtained with `get_beta_fit()`#' @param seed desired seed (default to `NULL`)#'#' @returns A list with two elements:#' - `res`: results for each estimated model of the grid. Each element is a#' list with the following elements:#' - `tb_metrics`: performance / calibration metrics#' - `tb_disp_metrics`: disp and div metrics#' - `tb_prop_scores`: table with P(q1 < score < q2)#' - `scores_hist`: histogram of scores.#' - `grid`: the grid search.simul_xgb_real <-function(data, target_name, prior,seed =NULL) {if (!is.null(seed)) set.seed(seed)# Split data into train and test set data_splitted <-split_train_test(data = data, prop_train = .7, seed = seed) data_encoded <-encode_dataset(data_train = data_splitted$train,data_test = data_splitted$test,target_name = target_name,intercept =FALSE )# Further split train into two samples (train/valid) data_splitted_train <-split_train_test(data = data_encoded$train, prop_train = .8, seed = seed)# Further split test into two samples (calib/test) data_splitted_test <-split_train_test(data = data_encoded$test, prop_train = .6, seed = seed)# Split prior scores# Further split train into two samples (train/valid) prior_splitted_train <-split_train_test_prior(prior = prior$scores_gamsel$scores_train, prop_train = .8, seed = seed)# Further split test into two samples (calib/test) prior_splitted_test <-split_train_test_prior(prior = prior$scores_gamsel$scores_test, prop_train = .6, seed = seed) res_grid <-vector(mode ="list", length =nrow(grid))for (i_grid in1:nrow(grid)) { res_grid[[i_grid]] <-simul_xgb_helper(data_train = data_splitted_train$train,data_valid = data_splitted_train$test,data_calib = data_splitted_test$train,data_test = data_splitted_test$test,prior_train = prior_splitted_train$train,prior_valid = prior_splitted_train$test,prior_calib = prior_splitted_test$train,prior_test = prior_splitted_test$test,target_name = target_name,params = grid |> dplyr::slice(i_grid),prior = prior ) }# The metrics computed for all set of hyperparameters (identified with `ind`)# and for each number of boosting iterations (`nb_iter`) metrics_simul <-map(res_grid, "tb_metrics") |>list_rbind()# P(q_1<s(x)<q_2) prop_scores_simul <-map(res_grid, "tb_prop_scores") |>list_rbind()# Decomposition of expected losses decomposition_scores_simul <-map(res_grid, "tb_decomposition_scores") |>list_rbind()# Histogram of estimated scores scores_hist <-map(res_grid, "scores_hist")list(metrics_simul = metrics_simul,scores_hist = scores_hist,prop_scores_simul = prop_scores_simul,decomposition_scores_simul = decomposition_scores_simul )}
8.4 Example: “spambase” dataset
We start to split the dataset “spambase” into train/validation/calibration/test sets.
data_splitted <-split_train_test(data = data, prop_train = .7, seed =1234)data_encoded <-encode_dataset(data_train = data_splitted$train,data_test = data_splitted$test,target_name = target_name,intercept =FALSE )# Further split train into two samples (train/valid)data_splitted_train <-split_train_test(data = data_encoded$train, prop_train = .8, seed =1234)# Further split test into two samples (calib/test)data_splitted_test <-split_train_test(data = data_encoded$test, prop_train = .6, seed =1234)# The different setsdata_train = data_splitted_train$traindata_valid = data_splitted_train$testdata_calib = data_splitted_test$traindata_test = data_splitted_test$test# Further split train into two samples (train/valid)prior_splitted_train <-split_train_test_prior(prior = prior$scores_gamsel$scores_train, prop_train = .8, seed =1234)# Further split test into two samples (calib/test)prior_splitted_test <-split_train_test_prior(prior = prior$scores_gamsel$scores_test, prop_train = .6, seed =1234)# The different setsprior_train = prior_splitted_train$trainprior_valid = prior_splitted_train$testprior_calib = prior_splitted_test$trainprior_test = prior_splitted_test$test
We try to fit and predict XGBoost with one set of hyperparameters. Here, we don’t need to use the validation set because we have specified the hyperparameters. In practice, hyperparameters will be selected based on different metrics (calibration, performance, dispersion) calculated on the validation set.
Let’s take the first row of the grid:
i_grid <-1params <- grid |> dplyr::slice(i_grid)# Parameters for the algorithmparam <-list(max_depth = params$max_depth, #Note: root node is indexed 0eta = params$eta,nthread =1,objective ="binary:logistic",eval_metric ="auc")
Next, we transform the different sets of the dataset in the right format to apply XGBoost:
Then, we estimate the scores at each boosting iteration to specify it for the final model, by using the function predict_score_iter(). We obtain a list of 400 elements, corresponding to the predicted scores at each iteration (total of 400 iterations for a specified XGBoost algorithm):
# As the xgb.Dmatrix objects cannot be easily serialised, we first estimate# these scores in a classical way, without parallelism...scores_iter <-vector(mode ="list", length = params$nb_iter_total)for (i_iter in1:params$nb_iter_total) { scores_iter[[i_iter]] <-predict_score_iter(fit_xgb = fit_xgb,tb_train_xgb = tb_train_xgb,tb_valid_xgb = tb_valid_xgb,tb_calib_xgb = tb_calib_xgb,tb_test_xgb = tb_test_xgb,nb_iter = i_iter )}
We are going to calculate different metrics for a single number of iterations (here 1 iteration only):
# Performance and Calibration Metrics----# We add very small noise to predicted scores# otherwise the local regression may crashscores_train_noise <- scores_train +runif(n =length(scores_train), min =0, max =0.01)scores_train_noise[scores_train_noise >1] <-1metrics_train <-compute_metrics(obs = data_train |>pull(!!target_name),scores = scores_train_noise, true_probas = prior_train ) |>mutate(sample ="train", recalib ="none")
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
Warning in ks.test.default(true_probas, scores): p-value will be approximate in
the presence of ties
8.5 Final results: “spambase” dataset
We calculate the performance/calibration/dispersion metrics for all iterations and all hyperparameters of the grid:
Let us extract all the histogram information computed over the simulations and put that in a single object, scores_hist_all.
scores_hist_all <- xgb_resul$scores_hist
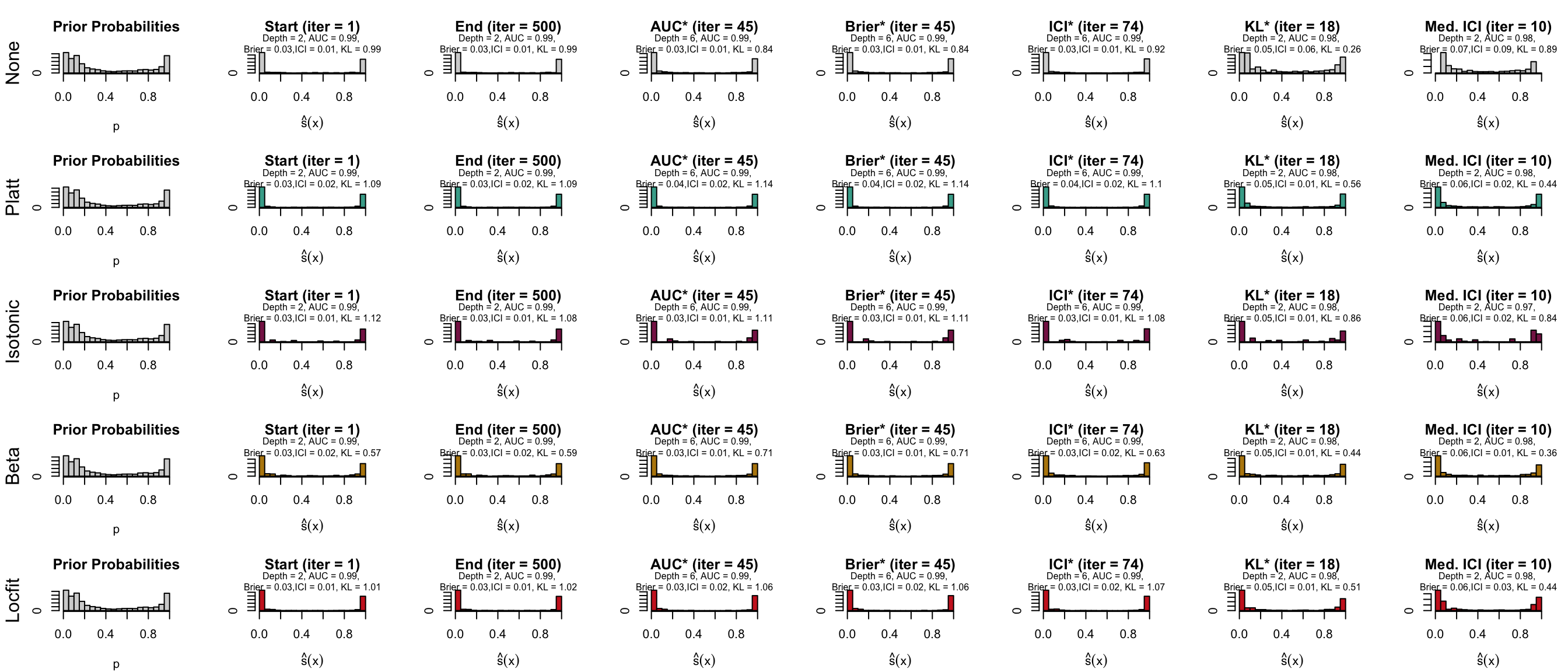
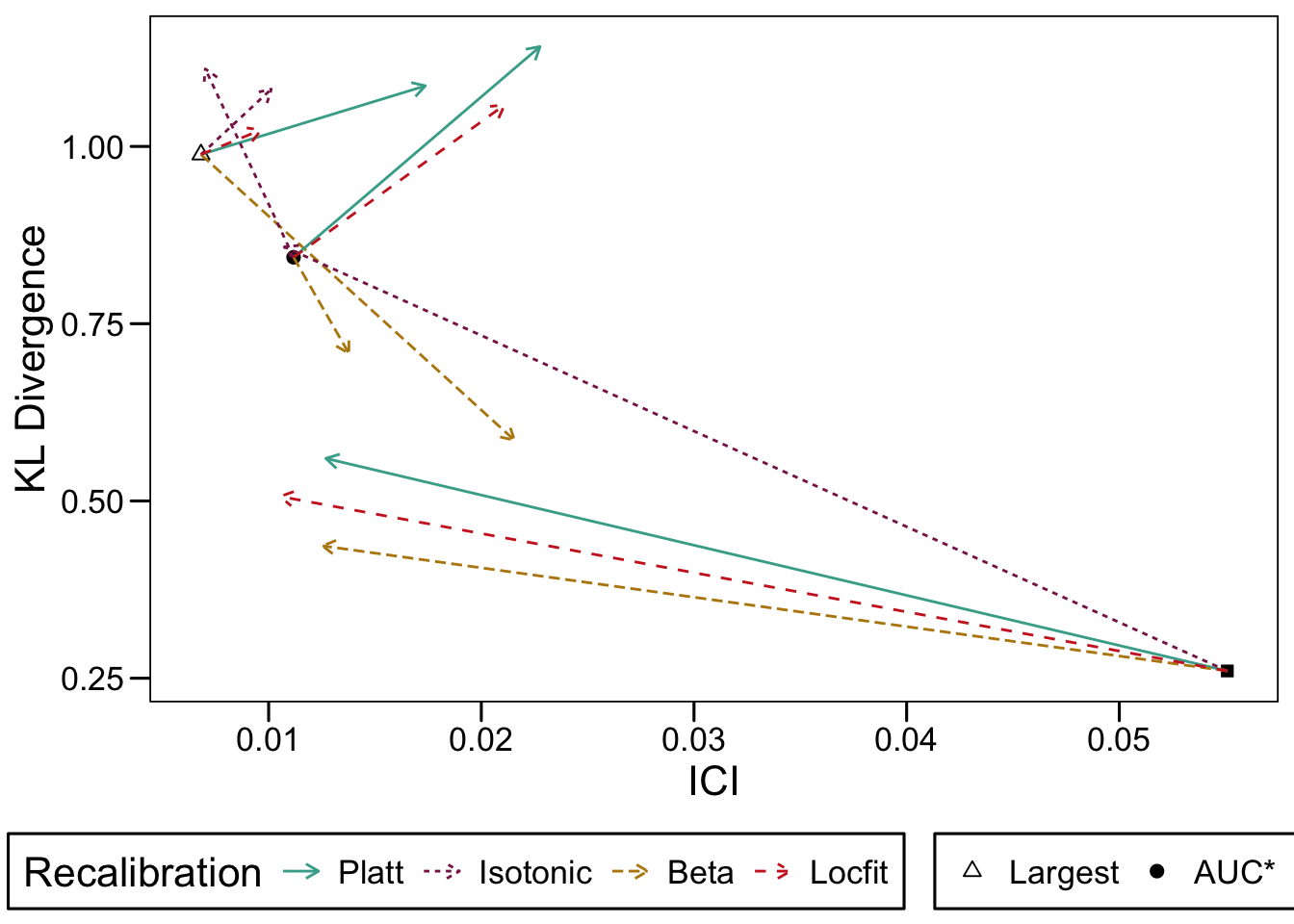
We then define a function, plot_bp_xgb() which plots the distribution of scores on the test set for the “spambase” dataset. We also define a helper function, plot_bp_interest(), which plots the histogram of the scores at a specific iteration number. We will then be able to plot the distributions at the beginning of the boosting iterations, at the end, at a point where the AUC was the highest on the validation set, and at a point where the KL divergence between the distribution of scores on the validation set and the distribution of the true probabilities was the lowest. We will plot the distributions of the scores returned by the classifier, as well as those obtained with the reclibrators.