── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(devtools)
Loading required package: usethis
library(ggtern)
Registered S3 methods overwritten by 'ggtern':
method from
grid.draw.ggplot ggplot2
plot.ggplot ggplot2
print.ggplot ggplot2
--
Remember to cite, run citation(package = 'ggtern') for further info.
--
Attaching package: 'ggtern'
The following objects are masked from 'package:ggplot2':
aes, annotate, ggplot, ggplot_build, ggplot_gtable, ggplotGrob,
ggsave, layer_data, theme_bw, theme_classic, theme_dark,
theme_gray, theme_light, theme_linedraw, theme_minimal, theme_void
# load the functions from our package to perform optimal transport on # compositional dataload_all("../../")
ℹ Loading transportsimplex
Definition of a ggplot2 theme.
#' Theme for ggplot2#'#' @param ... arguments passed to the theme function#' @export#' @importFrom ggplot2 element_rect element_text element_blank element_line unit#' reltheme_paper <-function(...) {theme(text =element_text(family ="Times New Roman"),plot.background =element_rect(fill ="transparent", color =NA),legend.text =element_text(size =rel(1.1)),legend.title =element_text(size =rel(1.1)),legend.background =element_rect(fill ="transparent", linetype="solid", colour ="black"),legend.position ="bottom",legend.direction ="horizontal",legend.box ="vertical",legend.key =element_blank(),panel.spacing =unit(1, "lines"),plot.title =element_text(hjust =0, size =rel(1.3), face ="bold"),plot.title.position ="plot",strip.background =element_rect(fill =NA, colour =NA),strip.text =element_text(size =rel(1.1)) )}
3.1 The Dataset
library(fairml)data(adult)
We want to build counterfactual values for the variable The categorical variable for which we want to build counterfactuals for the marital_status variable for women, had they been men. These are the raw categories:
Table 3.1: Proportions of each marital status for women and for men.
Proportions
sex
Married
Never-married
Separated
Female
0.1525
0.4408
0.4067
Male
0.6180
0.2657
0.1164
3.2 Estimation of Scores
We fit four models, \(\widehat{m}^{(k)}(\mathbf{x}_j|\mathbf{x}_{-j})\), using a multinomial loss, yielding predicted scores \(\widehat{\mathbf{x}}_{j}^{(k)}\in\mathcal{S}_d\) for \(k \in \{1,2,3,4\}\). The sensitive attribute \(s\). The income variable is also removed. The four models are:
GAM-MLR (1): A multinomial model with splines for two continuous variables and a third variable.
GAM-MLR (2): A multinomial model with adidtional variables.
Random Forest: A classifier using all available variables.
Gradient Boosting Model: A GBM trained on all available variables.
# weights: 63 (40 variable)
initial value 33136.343851
iter 10 value 25885.836959
iter 20 value 25131.762781
iter 30 value 24607.941350
iter 40 value 24439.499919
iter 50 value 24438.214321
final value 24438.207100
converged
# weights: 144 (94 variable)
initial value 33136.343851
iter 10 value 9899.654429
iter 20 value 9211.159339
iter 30 value 8206.013535
iter 40 value 7892.102459
iter 50 value 7614.929161
iter 60 value 7450.099601
iter 70 value 7386.503591
iter 80 value 7371.425003
iter 90 value 7367.283292
iter 100 value 7367.014720
final value 7367.014720
stopped after 100 iterations
The estimation of the random forest:
library(randomForest)
model_rf <-randomForest( marital_status ~ ., data = adult |>select(-sex, -income))
Table 3.2: Mappings from the marital_status categorical variable \(x\) to the compositional one \(\tilde{\mathbf{x}}\), for four individuals of the dataset.
Predicted Scores
marital_status
sex
Married
Never-married
Separated
GAM-MLR(1)
Never-married
Male
0.3523
0.2059
0.4418
Married
Male
0.5428
0.1054
0.3519
Married
Female
0.3026
0.5988
0.0986
Married
Female
0.5957
0.1710
0.2333
GAM-MLR(2)
Never-married
Male
0.0052
0.6323
0.3625
Married
Male
1.0000
0.0000
0.0000
Married
Female
1.0000
0.0000
0.0000
Married
Female
1.0000
0.0000
0.0000
Random Forest
Never-married
Male
0.0052
0.7565
0.2383
Married
Male
0.9944
0.0000
0.0056
Married
Female
0.9652
0.0348
0.0000
Married
Female
1.0000
0.0000
0.0000
Gradient Boosting Model
Never-married
Male
0.0034
0.6210
0.3757
Married
Male
0.9991
0.0003
0.0007
Married
Female
0.9980
0.0018
0.0001
Married
Female
0.9992
0.0005
0.0003
3.3 Optimal Transport in the Euclidean Representation
We can now apply Algorithm 1.1 with a Gaussian mapping in an Euclidean representation space to transport from observed \(\widehat{\mathbf{x}}_j|s=0\) (scores for women) to counterfactual \(\widehat{\mathbf{x}}_j|s=1\) (scores for men), in \(\mathcal{S}_d\).
Subset
We will work on a subset of the data here for the transport. Also, if the number is too large, the returned weights tend to be all equal to 1…
Then, we create matrices for each model with the predicted scores for each category, i.e., the representation of the categorical variable marital_status in the unit simplex.
For the random forest and the gradient boosting model, we add a tiny bit to scores exactly equal to zero and substract the same tiny bit to scores exactly equal to one.
We can then have a look at the percentage of each purpose category in the initial dataset, compare it with the average predicted score of each category for each model, and with the average of the transported predicted score for women.
Codes to create the Table.
# Proportions of each purpose level by gender in the datasetprop_marital <- adult |>count(marital_status, sex) |>group_by(sex) |>mutate(prop = n /sum(n)) |>select(-n) |>pivot_wider(names_from = marital_status, values_from = prop) |>mutate(type ="Categorical")get_table_pred_transp <-function(scores, transp_scores) {# Average predicted scores for each purpose level by gender mean_scores_by_gender <- adult_subset |>select(marital_status, sex) |>bind_cols(scores) |>group_by(sex) |>summarise(across(colnames(!!scores), ~mean(.x))) |>mutate(type ="Composition")# Average predicted transported score of women for each purpose level mean_transp_scores_women <-colMeans(transp_scores) |>as_tibble_row() |>mutate(type ="Transported", sex ="Female -> Male") mean_scores_by_gender |>bind_rows(mean_transp_scores_women)}tb_pred_transp_mean <- prop_marital |>mutate(model ="obs") |>bind_rows(get_table_pred_transp(scores_glm_1[idx, ], transp_glm_1) |>mutate(model ="glm_1") ) |>bind_rows(get_table_pred_transp(scores_glm_2[idx, ], transp_glm_2) |>mutate(model ="glm_2") ) |>bind_rows(get_table_pred_transp(scores_rf[idx, ], transp_rf) |>mutate(model ="rf") ) |>bind_rows(get_table_pred_transp(scores_gbm[idx, ], transp_gbm) |>mutate(model ="gbm") ) |>mutate(model =factor( model, levels =c("obs", "glm_1", "glm_2", "rf", "gbm"),labels =c("Observed Values","GAM-MLR(1)", "GAM-MLR(2)", "Random Forest", "Gradient Boosting Model" ) ) ) |>relocate(model, .before = sex) |>relocate(type, .after = model)tb_pred_transp_mean |>select(-model) |> kableExtra::kbl(booktabs =TRUE, digits =4,) |> kableExtra::kable_paper() |> kableExtra::add_header_above(c(" "=2, "Marital Status"=3)) |> kableExtra::pack_rows(index =table(tb_pred_transp_mean$model))
Table 3.3
Marital Status
type
sex
Married
Never-married
Separated
Observed Values
Categorical
Female
0.1525
0.4408
0.4067
Categorical
Male
0.6180
0.2657
0.1164
GAM-MLR(1)
Composition
Female
0.3524
0.3965
0.2510
Composition
Male
0.5040
0.3104
0.1856
Transported
Female -> Male
0.4908
0.3213
0.1879
GAM-MLR(2)
Composition
Female
0.1333
0.4605
0.4062
Composition
Male
0.5959
0.2732
0.1309
Transported
Female -> Male
0.7760
0.0780
0.1461
Random Forest
Composition
Female
0.1316
0.4871
0.3813
Composition
Male
0.5929
0.2769
0.1302
Transported
Female -> Male
0.4867
0.3337
0.1796
Gradient Boosting Model
Composition
Female
0.1353
0.4604
0.4043
Composition
Male
0.5950
0.2754
0.1296
Transported
Female -> Male
0.5165
0.3137
0.1698
Optimal transport using the clr transformation, and Gaussian optimal transports, on the purpose scores in the German Credit database, with two logistic GAM models to predict scores, a random forest, and a boosting model. For observed values, the observed proportions of purpose categories are reported by gender. Then, for each model, the average of predicted scores by gender for each categories are shown (Composition). Lastly, the average of transported predicted scores for women are reported (Transported).
3.3.1 Visualization of Transported Categories
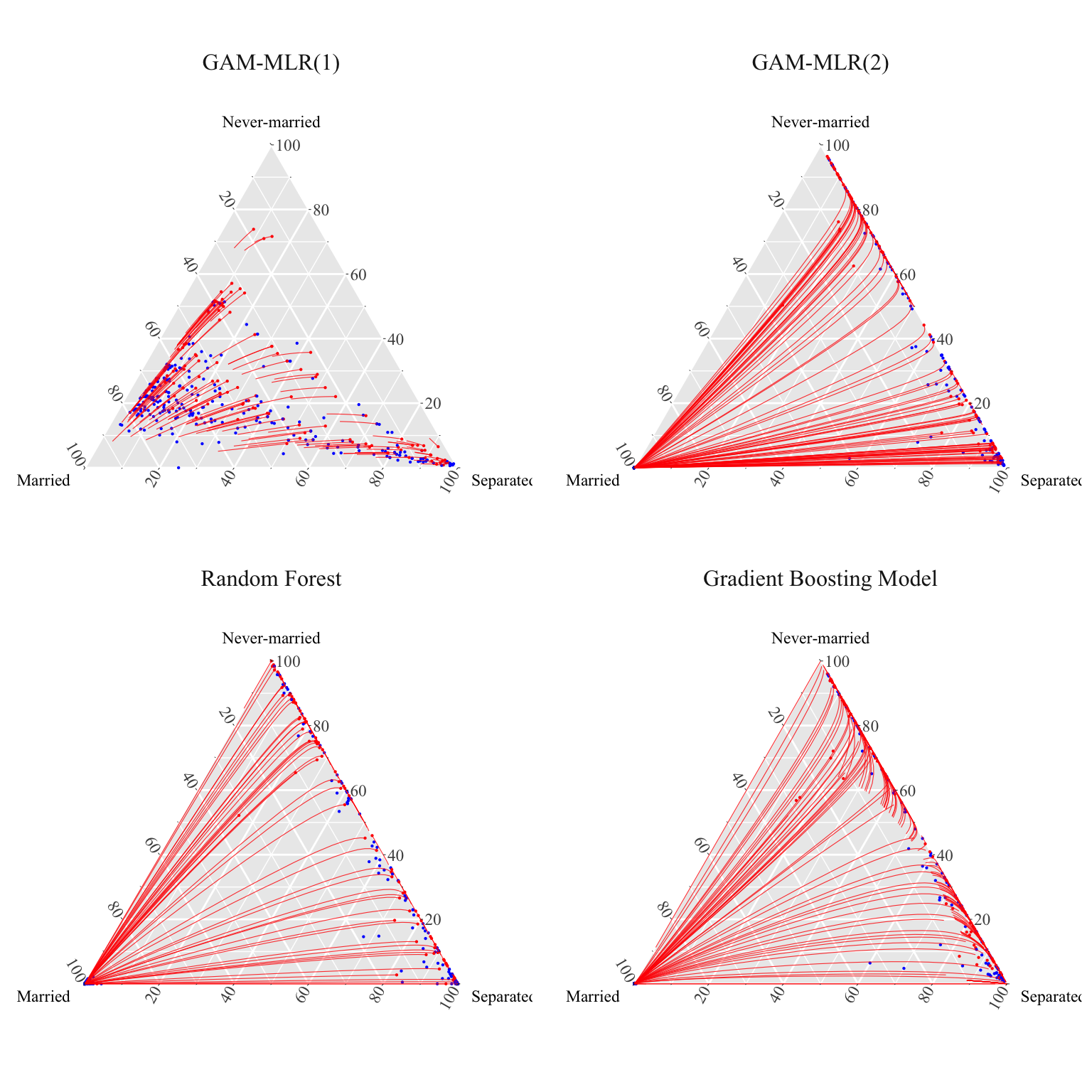
We can then show the counterfactuals on a ternary plot, and graph the displacement interpolation when generationg from the factual (women) to the counterfactuals (men).
Then, we can show, for each model, the representation in the simplex of the categorical variable marital_status, by gender (women in red and men in blue), as well as the displacement interpolation.
Figure 3.1: Optimal Transport using clr transform. Points in red are compositions for women, whereas points in blue are compositions for men. The lines indicate the displacement interpolation when generating counterfactuals.
3.4 Optimal Transport in \(\mathcal{S}_3\)
Let us now use Algorithm 1.2 to create counterfactuals using matching in \(\mathcal{S}_3\).
To that end, we use the wasserstein_simplex() function from our package.
Note
The codes are a bit long to run. Here, we load results saved from a previously evaluated code.
For each model, we extract the representation of the marital_status characteristic in the simplex (i.e., the predicted scores by the \(k\)-th model, \(\widehat{m}^{(k)}(\mathbf{x}_j|\mathbf{x}_{-j})\)). Let us denote this composition as \(\mathbf{x}_{0,i}^{(k)}\)
Lastly, we compute, for our individual, its counterfactual \(T^\star(\mathbf{x}_{0,i})\), by simply computing the weighted average of the characteristics of the individuals from the other group.
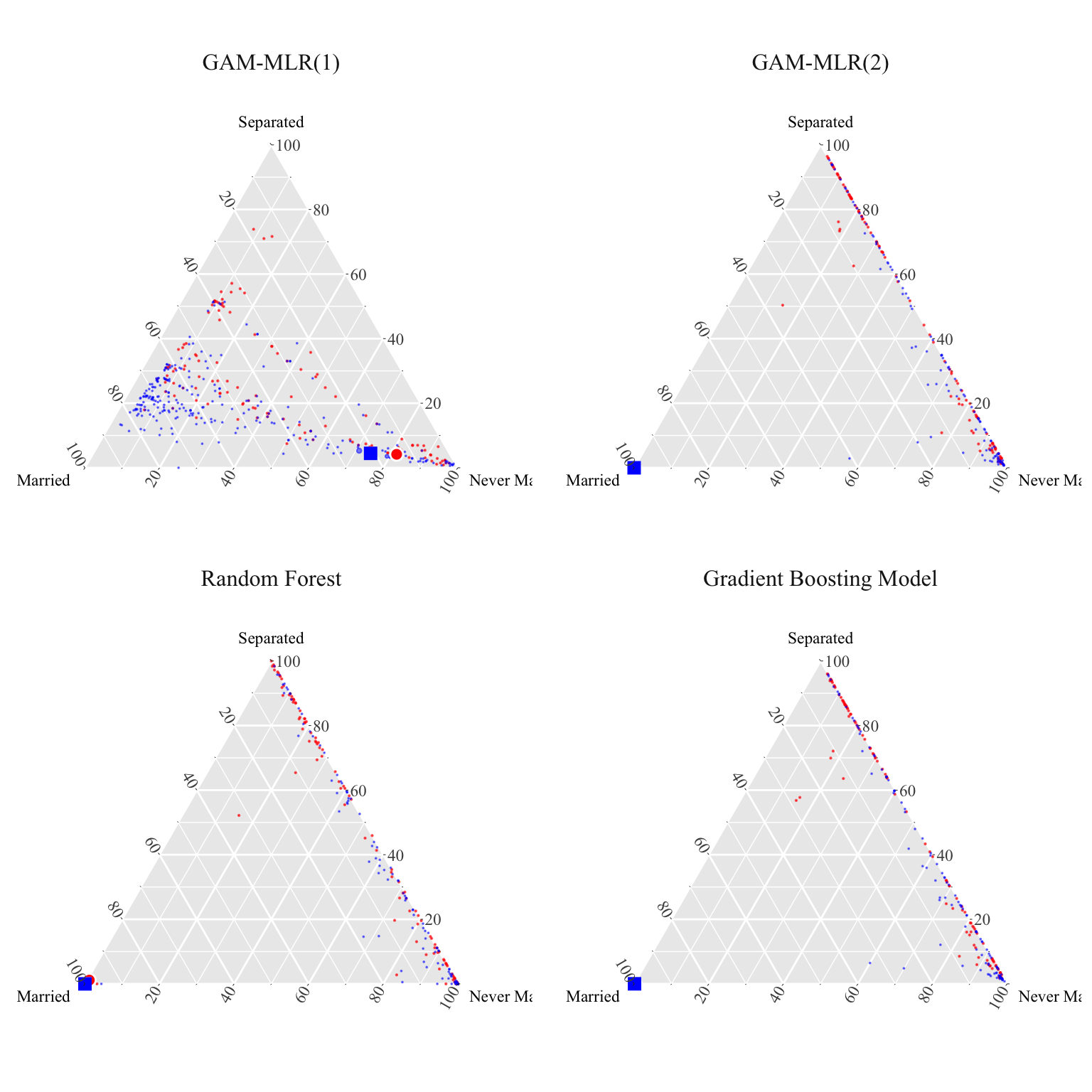
We can then plot (Figure 3.2) the representation of the woman of interest obtained for each model (red dot), and its counterfactual obtained by matching (blue dot). We also plot, on the ternary plot, all the women and men. The size of the dots for men is proportional to the weights corresponding to the women of interest.
Figure 3.2: Empirical matching of a woman\(\mathbf{x}_{0,i}^{(k)}\) (big red dot) with men (blue dots). The Size of blue dots are proportional to the weights \(\mathbf{P}^\star_i\). The counterfactual obtained with matching \(T^\star(\mathbf{x}_{0,i})\) is shown as a blue square.
To finish, let us look more closely to the i-th woman for which we have shown the counterfactual on the ternary plot. The value of the marital_status variable for her is Married:
adult_subset[ind_0[i], "marital_status"]
[1] Married
Levels: Married Never-married Separated
Using the GAM-MLR(1) model, we obtained the following composition:
X0_glm_1[i, ]
Married Never-married Separated
0.14317730 0.81513857 0.04168414
The closest points in the group of men, obtained using Algorithm 1.2 are: