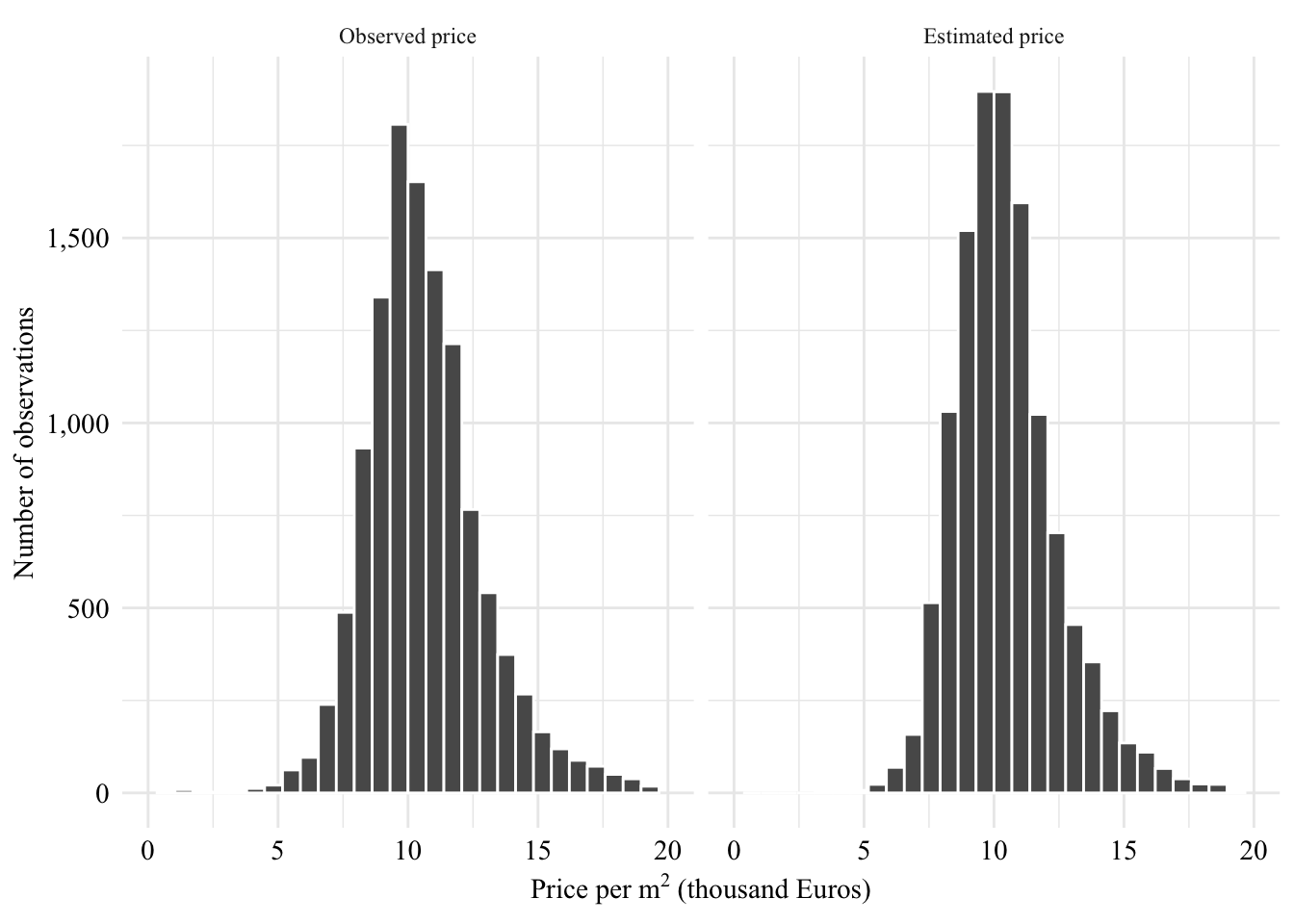
The data come from Meilleurs Agents, a French Real Estate platform that produces data on the residential market and operates a free online automatic valuation model (AVM).
load("../data/raw/base_immo.RData")
1.2 Global Summary Statistics
We have access to both the estimated price \(\hat{Z}\) of the underlying property and realized net sale price \(Z\). We also have access to the approximate location and amount of square meters (\(m^2\)) of the property.
We restrict our observations to cases where all the information is available.
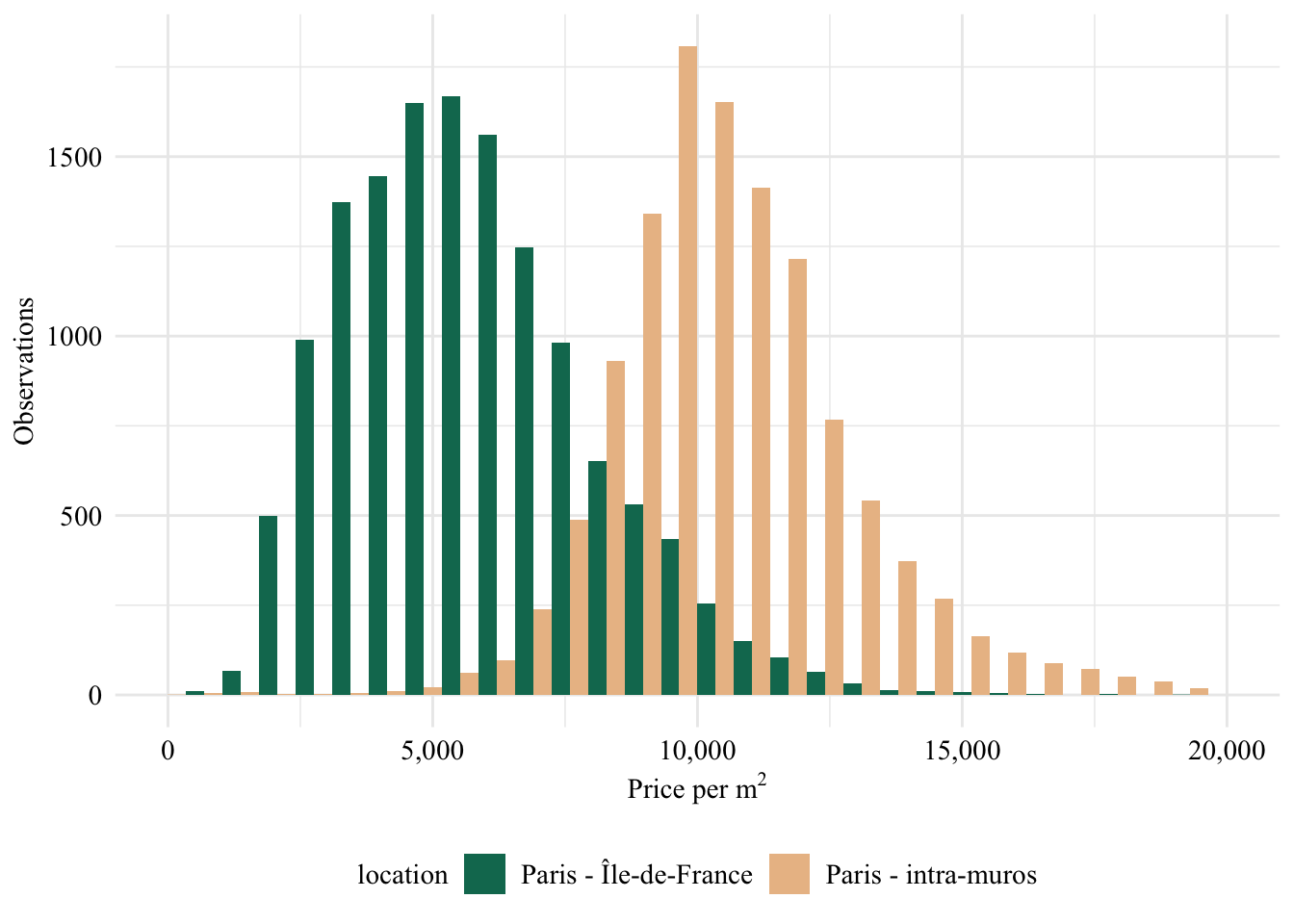
There are 25,675 observation in the dataset. Let us have a look at the number of observations depending on the city. The dataset encompasses data from Paris intra-muros and from other cities within the French departement `Île-de-France’.
Figure 1.1: Price per square meter in different areas of our data. Paris intra-muros refers to the 20 arrondissements that constitute the core of the city, Ile de France refers to the remaining metropolitan area.
Let us remove outliers with a price per square meter of over €20,000 and observations from mostly commercial areas.
data_immo <- data_immo |>filter(pm2 <=20000)
In all, we then have access to 11,812 observations after these basic cleaning steps.
1.3 IRIS
Our Data contains geospatial information, aggregated at the IRIS (Ilots Regroupés pour l’Information Statistique) level, a statistical unit defined and published by the French National Institute of Statistics and Economic Studies.1 The city of Paris is divided into 20 arrondissements. Each IRIS located in Paris belongs to a single arrondissement.
Tip
Three types of IRIS are distinguished:
Residential IRIS: their population generally ranges between 1,800 and 5,000 inhabitants. They are homogeneous in terms of housing type, and their boundaries are based on major breaks in the urban fabric (main roads, railways, watercourses, …).
The IRIS for economic activity: they bring together more than 1,000 employees and have at least twice as many salaried jobs as resident population;
Miscellaneous IRIS: these are large, specific, sparsely populated areas with significant surface areas (amusement parks, port areas, forests, …).
The welth level per IRIS comes from the `Revenus, pauvreté et niveau de vie en 2020 (Iris)’ distributed by the National Institute of Statistics and Economic Studies (INSEE). The data can be downloaded free of charge at the following addreess: https://www.insee.fr/fr/statistiques/7233950#consulter.
From the Parisian map, we extract some information at the IRIS level: the name of the arrondissement (NOM_COM), the name of the IRIS (NOM_IRIS), and the type of IRIS (TYP_IRIS).
This information can be added to the real estate data. We will also add income data at the IRIS level in the dataset and define a new categorical variable: income_class which takes three values:
"rich" if the income in the IRIS is larger or equal to €35,192,
"poor" if the income in the IRIS is lower or equal to €20,568,
Warning: There was 1 warning in `mutate()`.
ℹ In argument: `median_income = as.numeric(median_income)`.
Caused by warning:
! NAs introduced by coercion
1.5 Export Data
We restrict ourselves to the residential IRIS (type "H") and to sales where both the estimated and the observed price per square meter was below 20,000.