In the previous chapters, we explored how to construct counterfactuals for a categorical variable by mapping individuals from one group (group 0) to another (group 1). We considered three approaches: random matching (Chapter 11), optimal transport based on arbitrarily assigned numerical values to the categories (Chapter 9), and optimal transport using a representation in the probability simplex (Chapter 10). In this chapter, we illustrate these methods on a small example involving six individuals in each group, and compare the resulting counterfactual assignments for the categorical variable.
As in the previous chapters, assume two groups: 0 and 1. In the first group, there are \(n_0=6\) individuals indexed 1, 2, 3, 4, 5, 6; and in group 1, there are \(n_1=6\) individuals indexed 7, 8, 9, 10, 11, 12. Let \(Y\) denote a response variable that takes values in \(\mathbb{R}\), and let \(X\) be a categorical variable taking values \(\{A,B,C\}\).
Let us assume that we obtained the estimated probabilities of being in each class using a multinomial regression model. This allows to convert categorical observations \(\{x_{1,1},\cdots,x_{1,n_1}\}\) and \(\{x_{0,1},\cdots,x_{0,n_0}\}\) into estimated probabilities, \(\{\boldsymbol{p}_{1,1},\cdots,\boldsymbol{p}_{1,n_1}\}\) and \(\{\boldsymbol{p}_{0,1},\cdots,\boldsymbol{p}_{0,n_0}\}\).
There are \(6!=720\) different random matching that can be done. We will show two of them below.
11.1.1 First Random Matching
Let us first consider a random matching in which the individuals matched are 1 (group 0) and 12 (group 1), 2 and 9, 3 and 7, 4 and 10, 5 and 8, 6 and 12.
We can consider, for the sake of illustration, a second random matching, where the individuals matched are 1 and 8, 2 and 7, 3 and 11, 4 and 10, 5 and 9, 6 and 12.
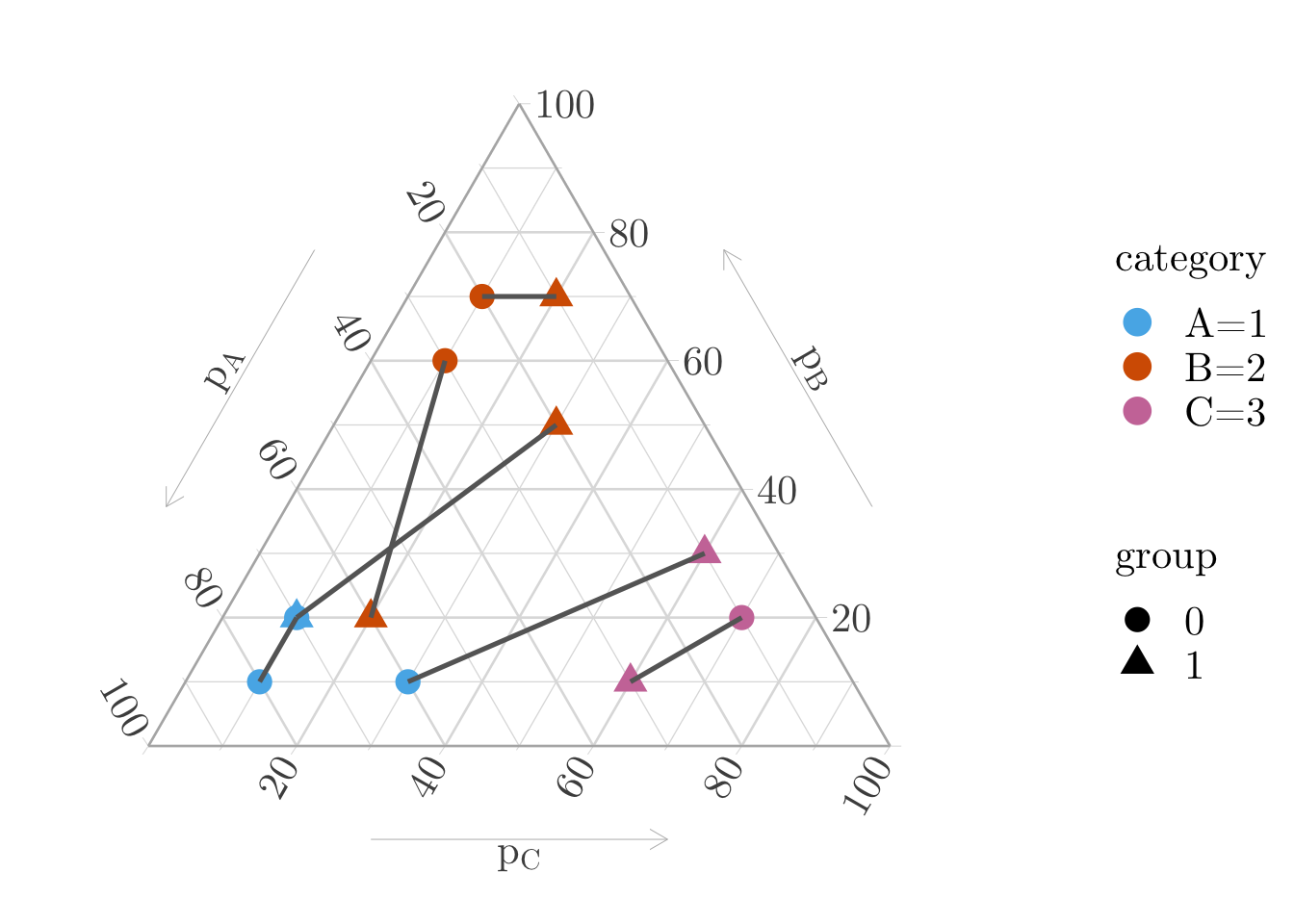
Figure 11.1: 1-to-1 Matching with optimal transport based on the distances between the individuals with respect to the abrbitrarily assigned numerical values to the categories.
11.3 Transport on Simplex
Let us now perform optimal matching between individuals from the two groups with optimal transport using a representation in the probability simplex.s
11.3.1 Matching Using the Euclidean Distances Cost Matrix
Let us use the Euclidean distance for the transport costs. These distances are computed in the space of centered log-ratio (clr) transformed probability vectors associated with each individual’s membership in one of the classes.
Let us first extract the probability vectors (\(p_A, p_B, p_C\)) from both groups and apply the clr transformation to make them suitable for Euclidean geometry in the compositional space.
Then, we can compute the pairwise Euclidean distances between individuals in group 0 and those in group 1, based on their clr-transformed probability vectors.
row.names(all_coords) <-c(group_0$i, group_1$i)# Euclidean distances between the clr transform of the propensitiesD <-as.matrix(dist(all_coords, method ="euclidean"))n0 <-nrow(group_0)n1 <-nrow(group_1)between_distances <- D[1:n0, (n0 +1):(n0 + n1)]round(between_distances, 2)
We aim to find the optimal matching between the individuals in group 1 and group 0 based on these distances. Formally, we want to solve the following optimal transport problem: \[
\min_{P\in\mathcal{U}(\boldsymbol{1}_{n_1},\boldsymbol{1}_{n_0})}
\langle P,\,C\rangle,
\] where \(C:=[C_{i,j}]\) is the cost matrix, with \(C_{ij}\) measuring the cost of matching individual \(i\) from group 1 to individual \(j\) from group 0. Here, we use the Euclidean distance that we juste computed. The total cost is given by \(\langle P, C\rangle=\sum_{i=1}^{n_1}\sum_{j=1}^{n_0}P_{ij}\,C_{ij}\). The set of admissible transport plans is defined as follows: \[
\left\{\,P\in\mathbb{R}_+^{n_1\times n_0}:
P\,\mathbf{1}_{n_0}=\frac{\mathbf{1}_{n_1}}{n_1},\
P^\top\mathbf{1}_{n_1}=\frac{\mathbf{1}_{n_0}}{n_0}
\right\}.
\] We thus have a uniform mass distribution across both groups.
Note
An alternative cost function (which is not used here) is the cross-entropy between two compositional vectors: \[
\begin{equation*}
c(\mathbf{x},\mathbf{y})=\log\left(\frac{1}{d}\sum_{i=1}^d\frac{y_i}{x_i}\right)-\frac{1}{d}\sum_{i=1}^d\log\left(\frac{y_i}{x_i}\right),
\end{equation*}.
\] This corresponds to the “Dirichlet transport” (Baxendale and Wong (2022)). This alternative is considered below, in Section 11.3.2.
We solve the optimal transport problem using the transport() function from the {transport} package. This function computes the optimal matching plan based on the cost matrix.
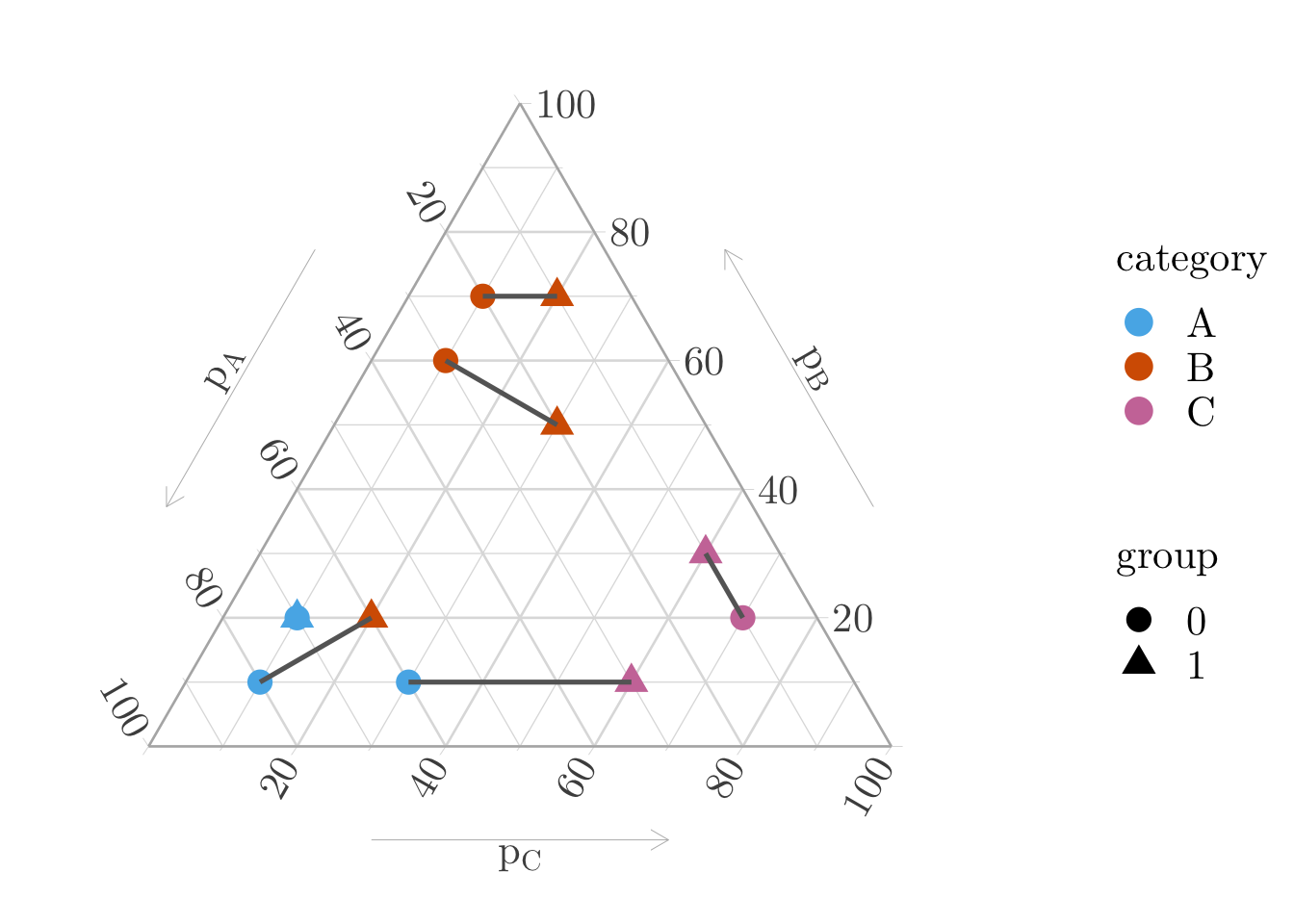
Figure 11.2: 1-to-1 Matching with optimal transport based on the distances between the individuals with respect to their estimated probabilities of being in each class.
11.3.2 Matching Using the Cross-Entropy Cost Matrix
In Section 11.3.1, we used the Euclidean distance of the clr-transformed vector of probabilities as the cost function to solve the optimal transport problem. Here, we consider an alternative cost function, the cross-entreopy: \[
c(\mathbf{x}, \mathbf{y}) = \log\left(\frac{1}{d} \sum_{i=1}^d \frac{y_i}{x_i}\right) - \frac{1}{d} \sum_{i=1}^d \log\left(\frac{y_i}{x_i}\right).
\]
We first extract the probability vectors for the individuals from both groups (without clr transform), and we make sure there is no probability equal to 0.
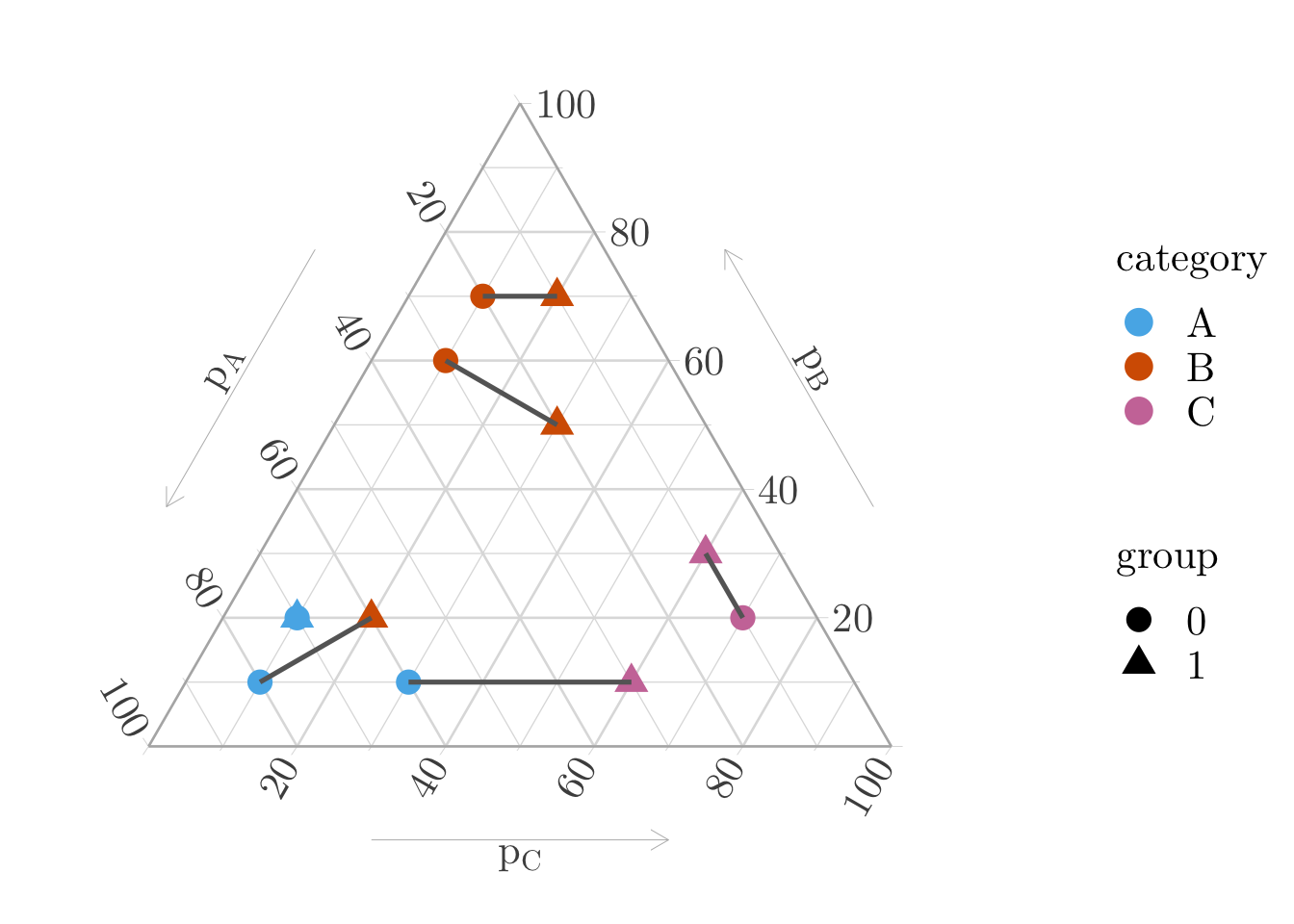
Figure 11.3: 1-to-1 Matching with optimal transport based on cross entropy as the transport cost between the individuals with respect to their estimated probabilities of being in each class.
Baxendale, Peter, and Ting-Kam Leonard Wong. 2022. “Random Concave Functions.”The Annals of Applied Probability 32 (2): 812–52.