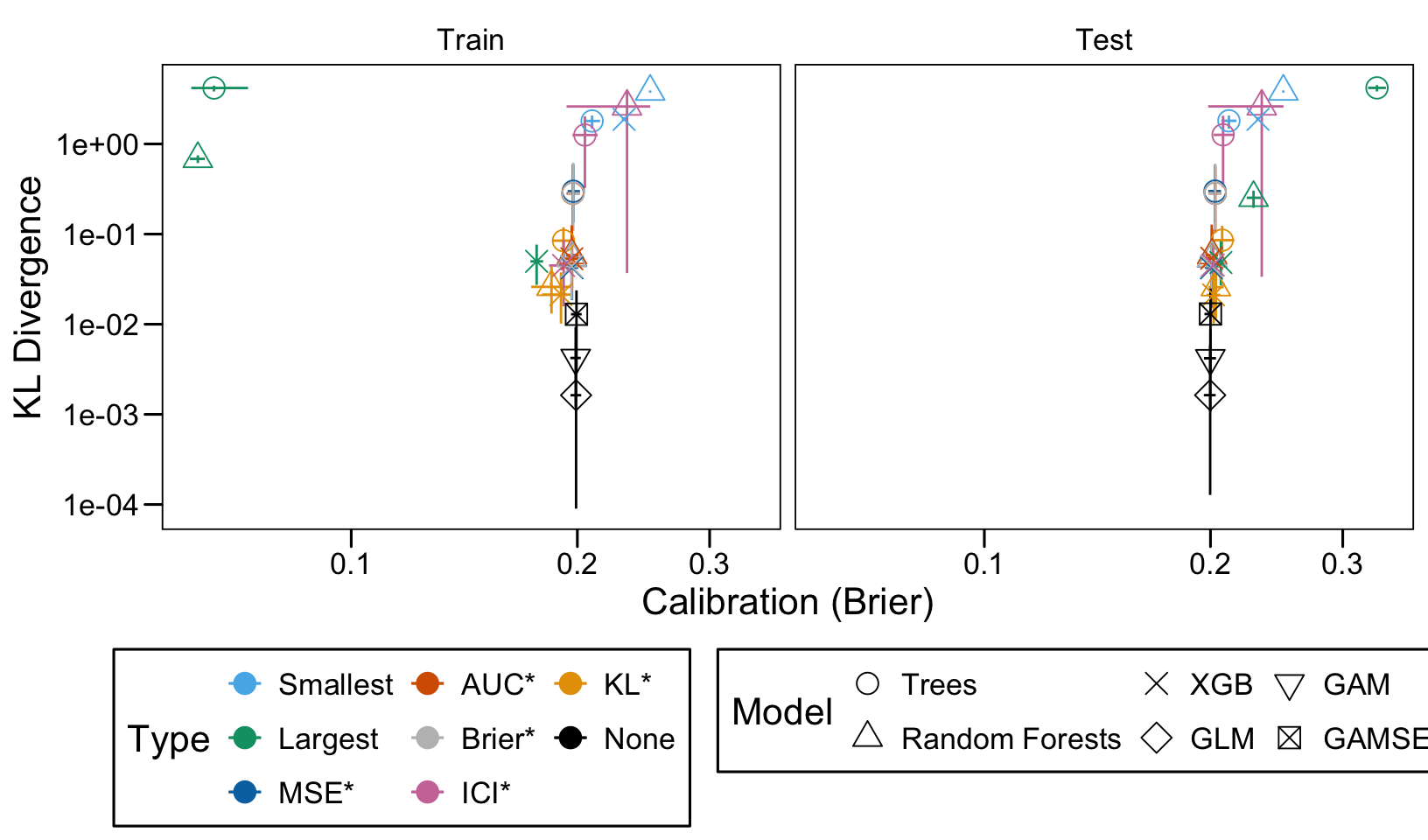
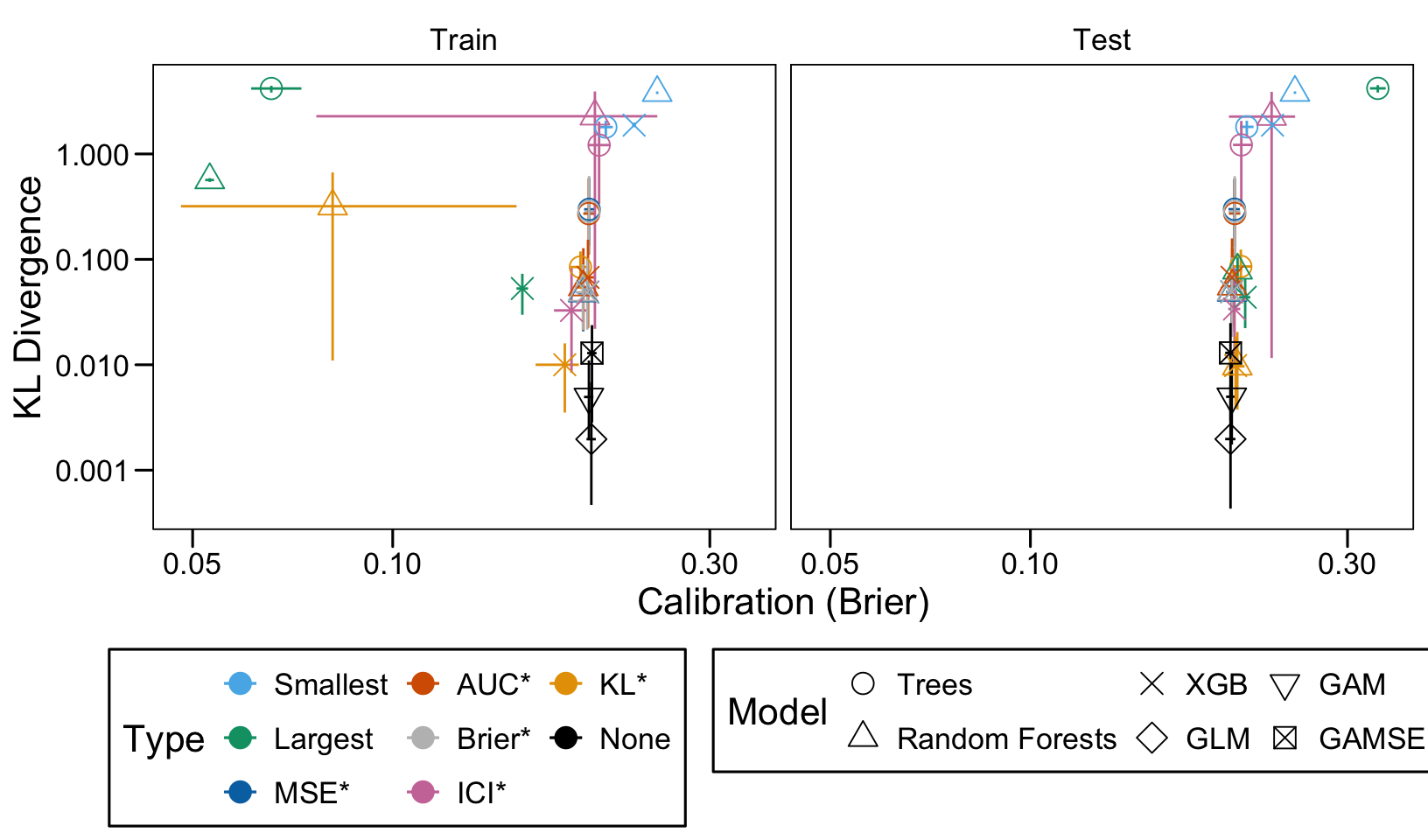
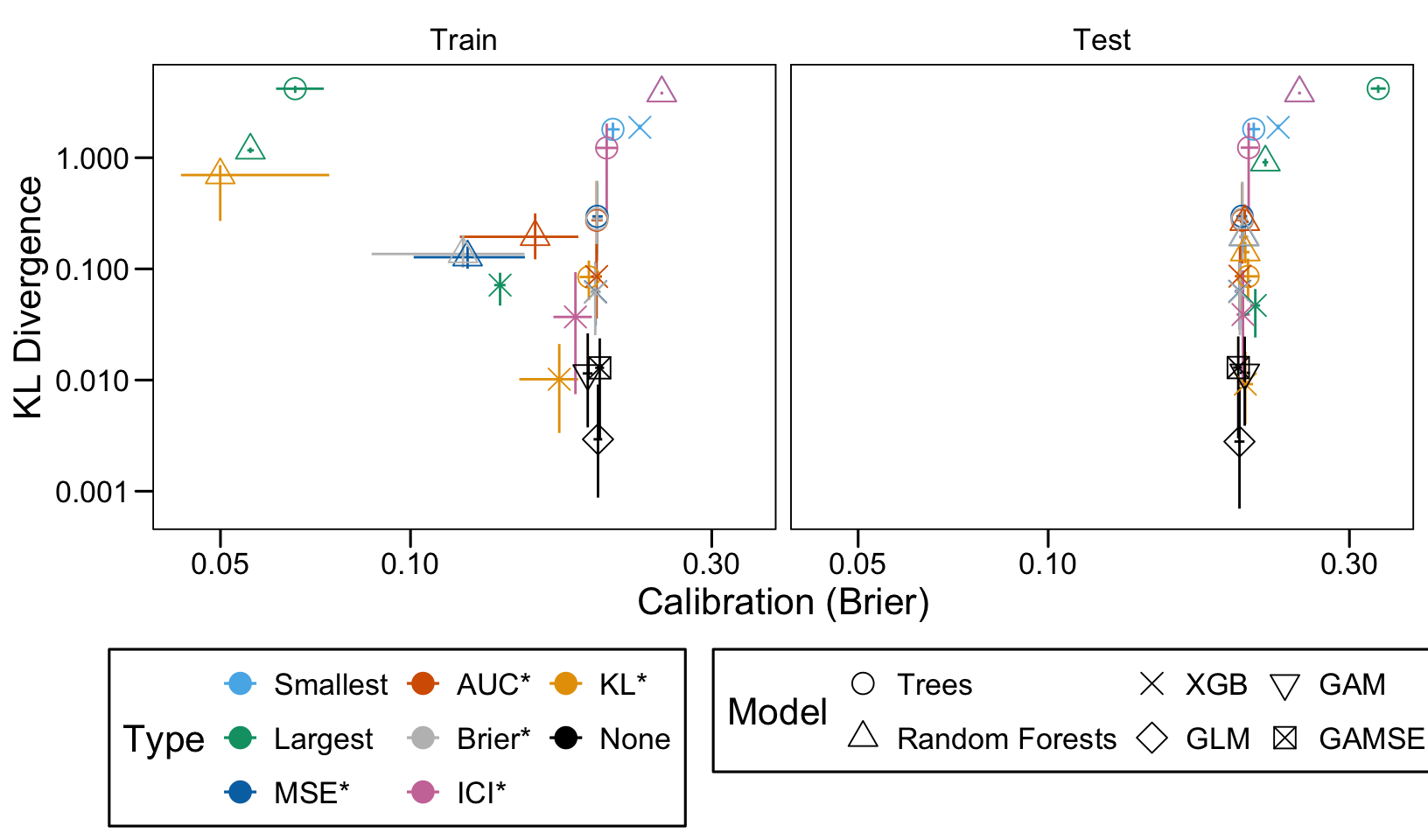
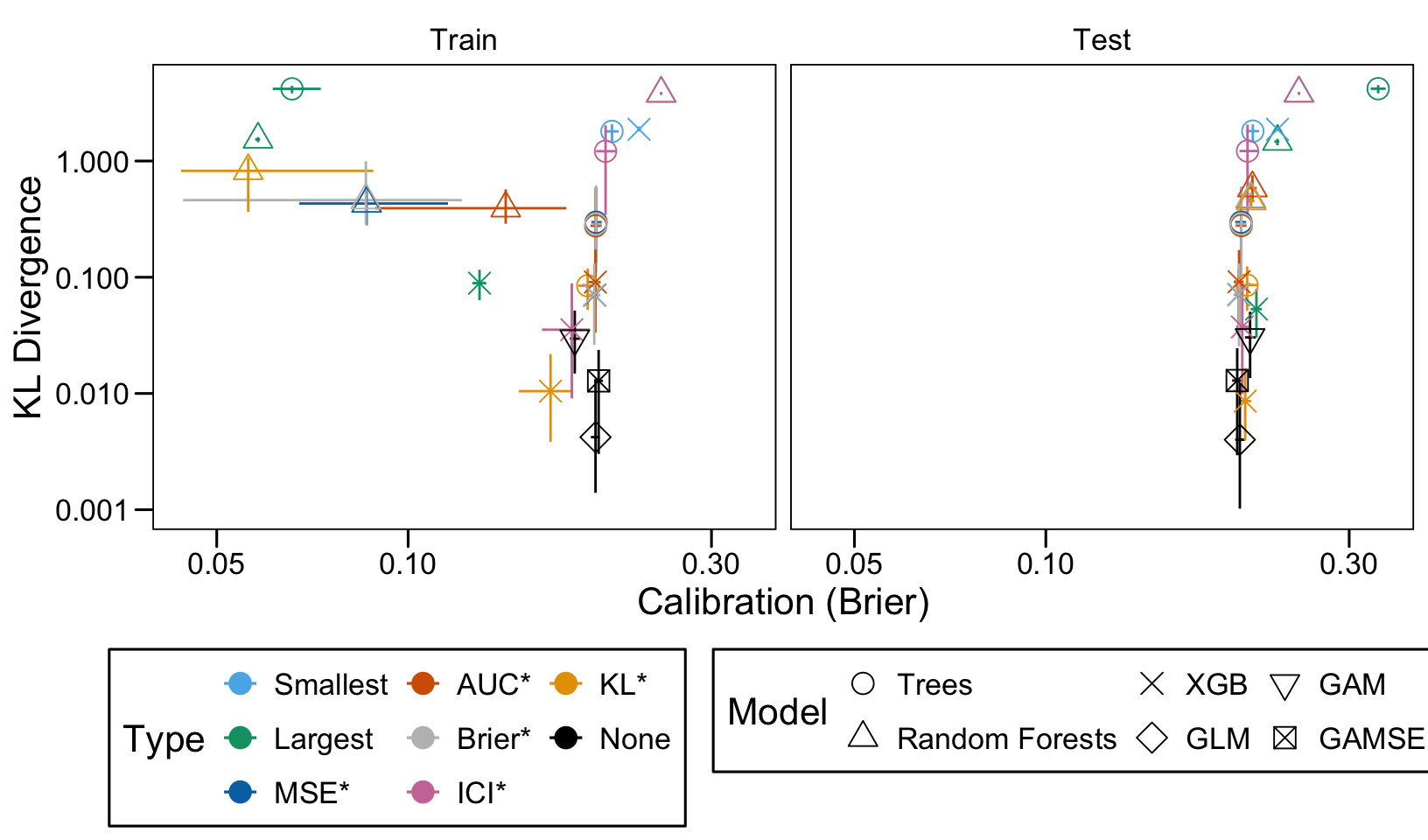
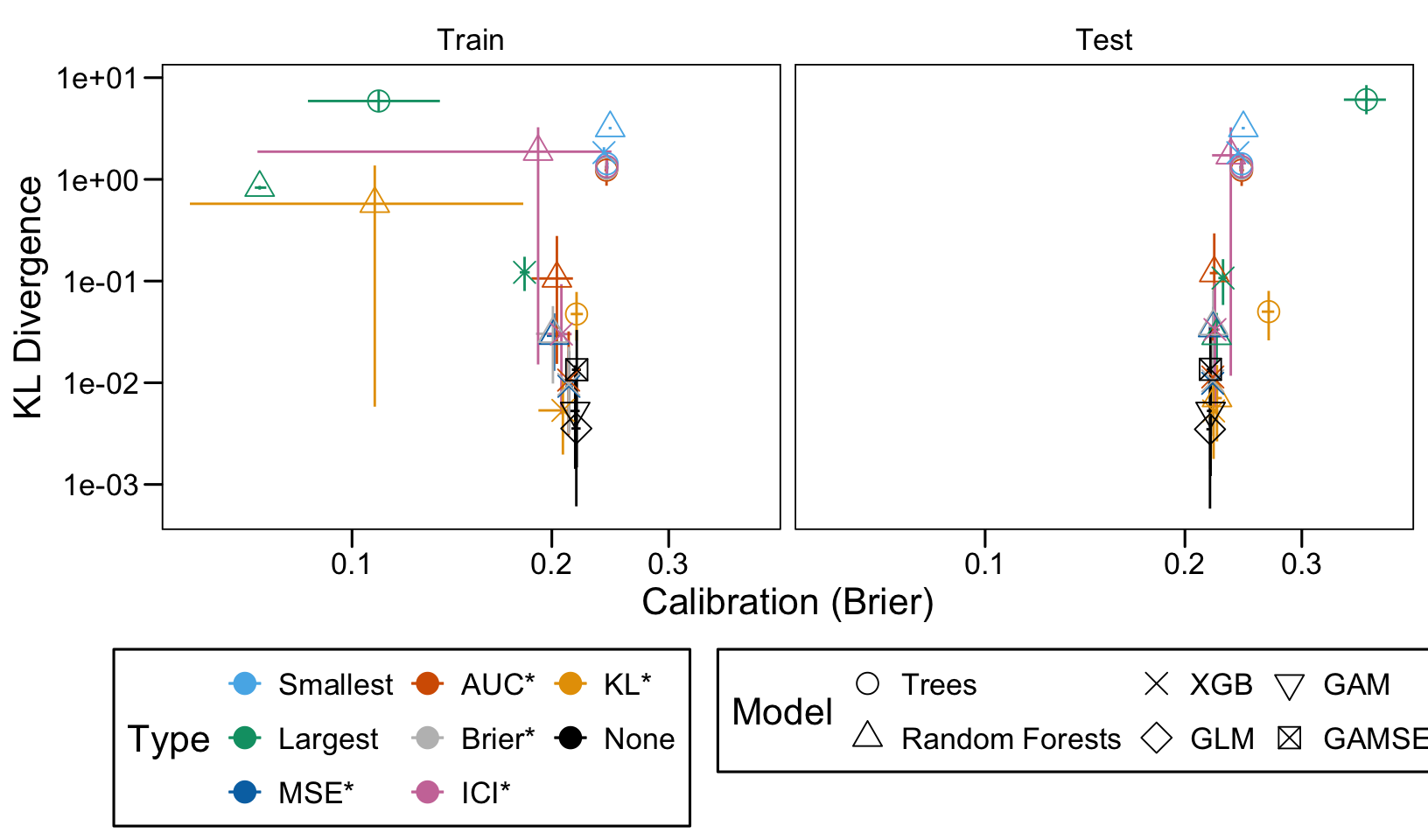
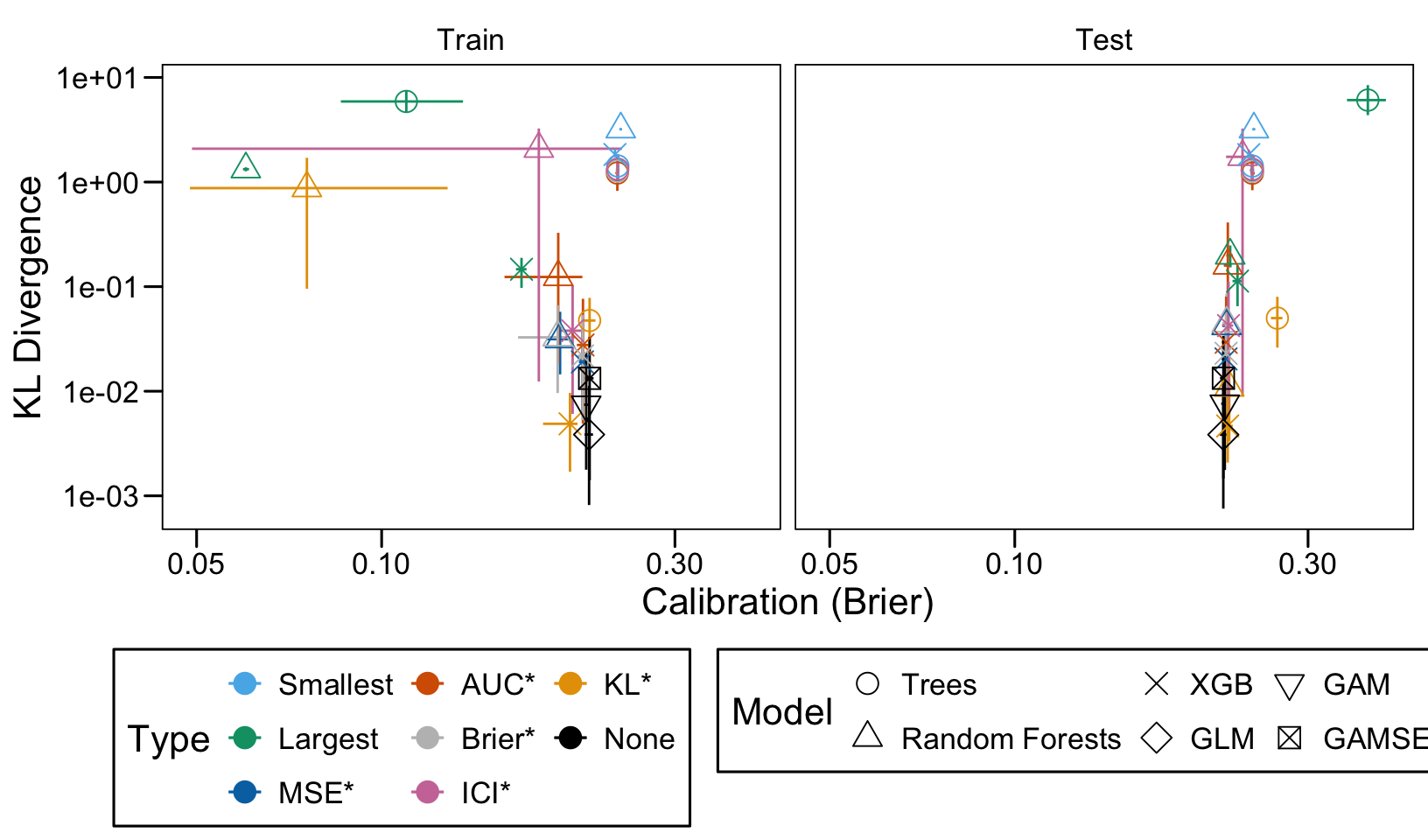
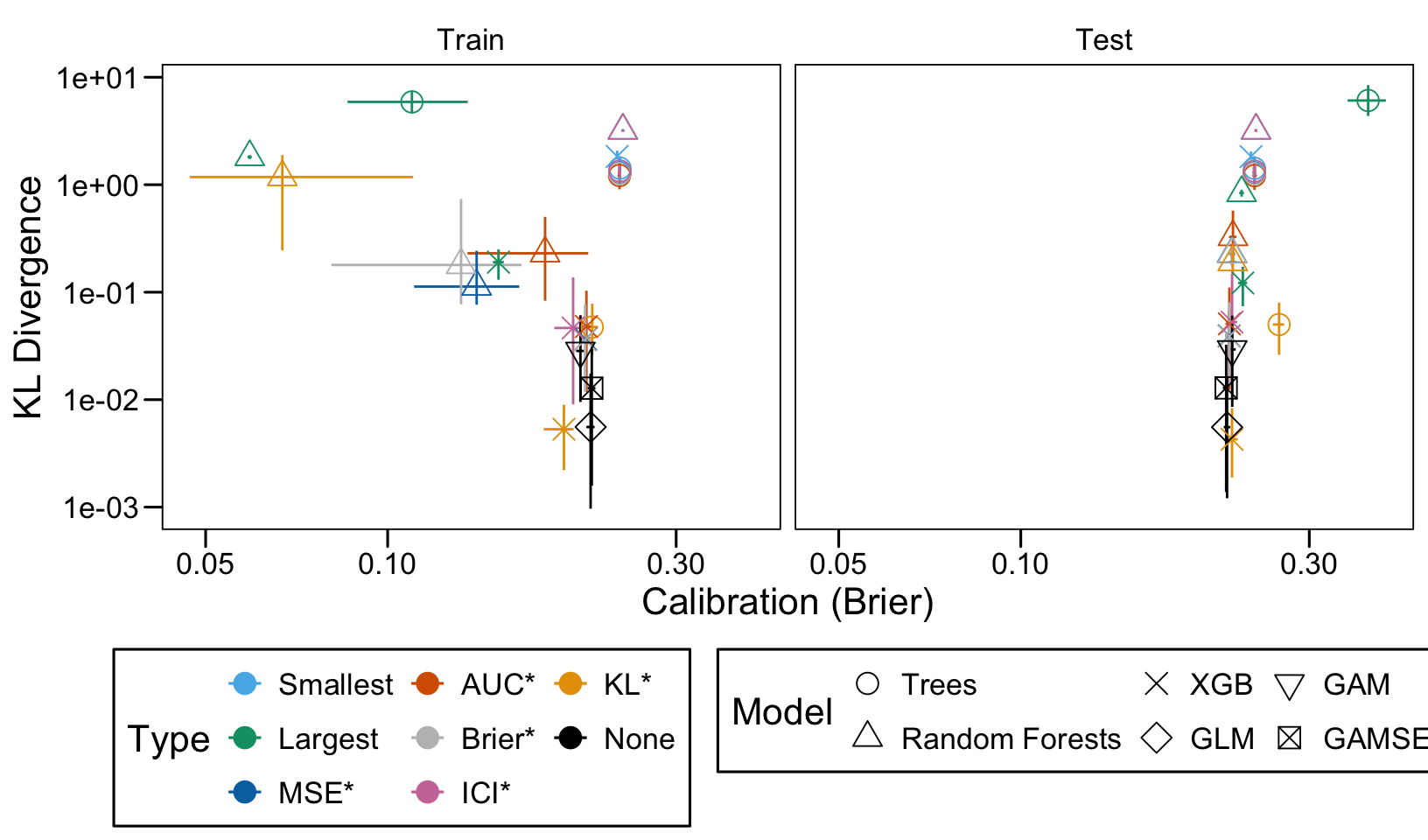
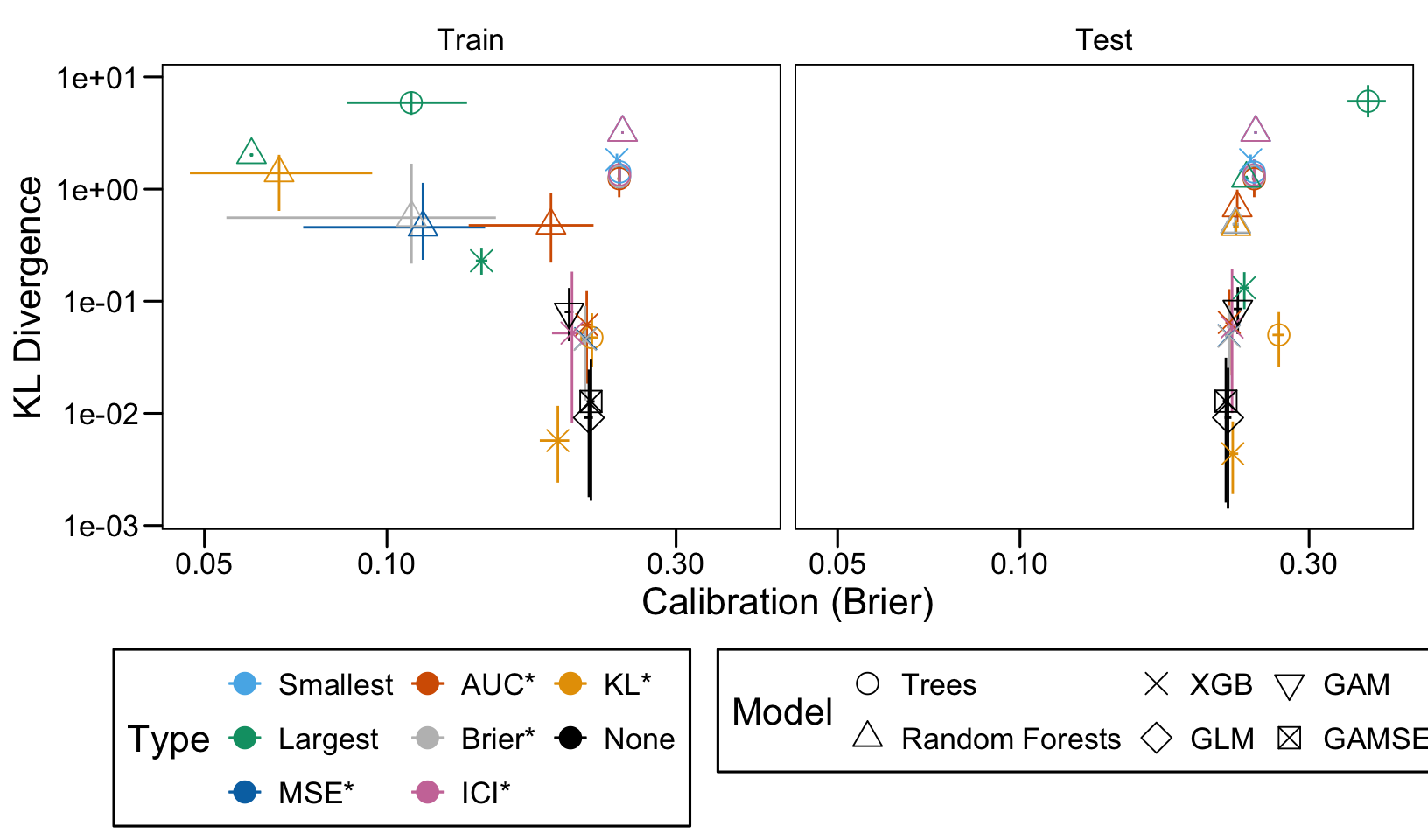
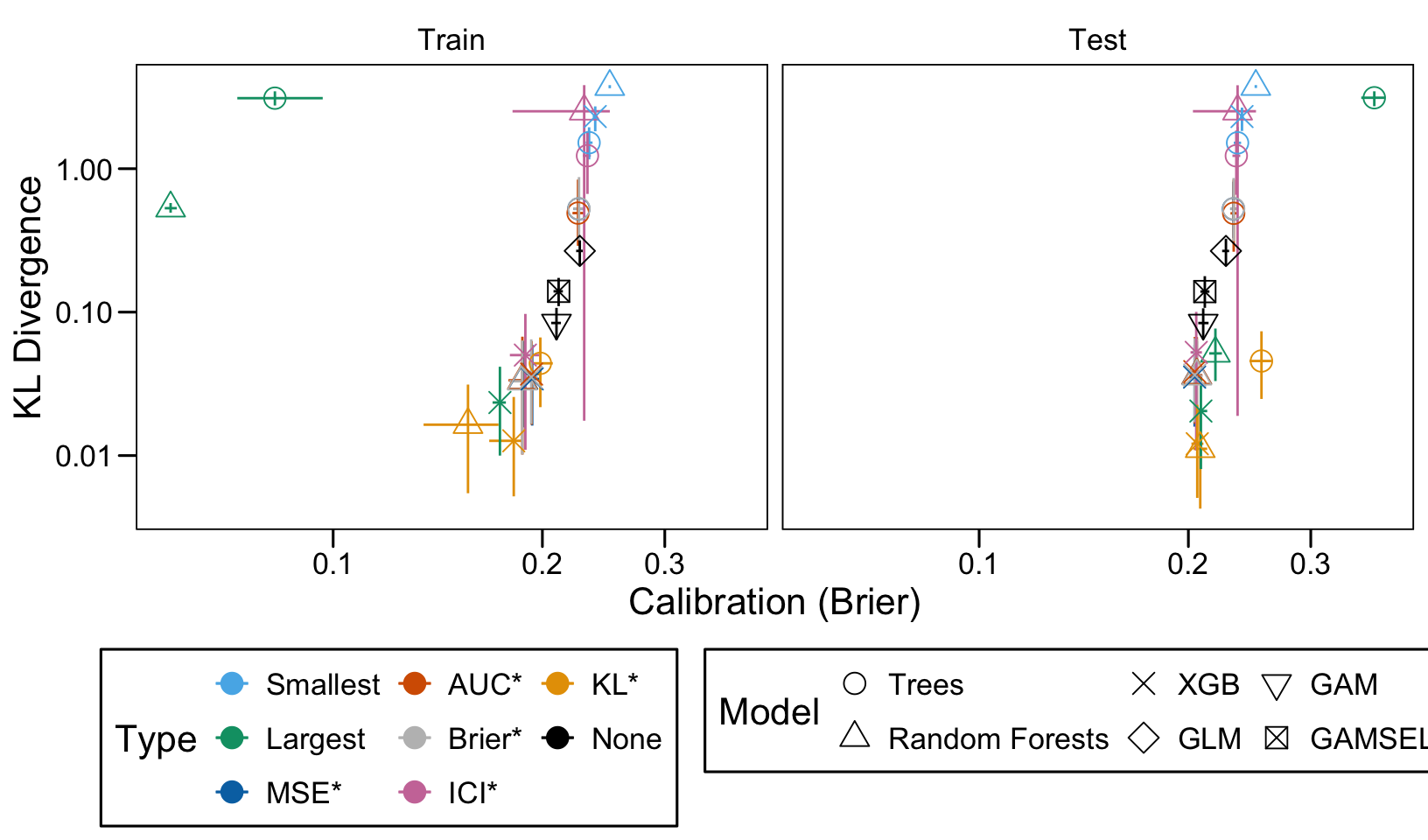
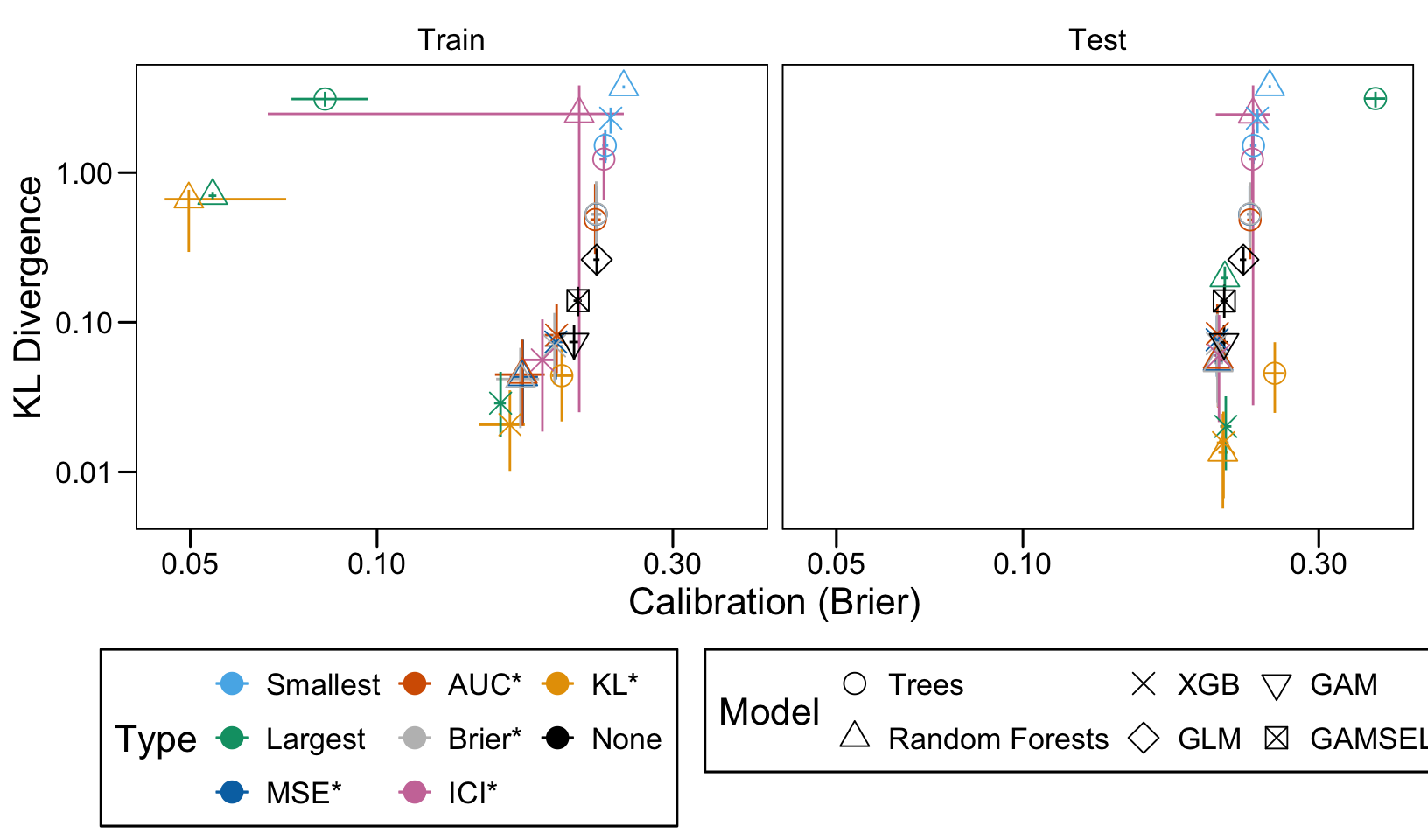
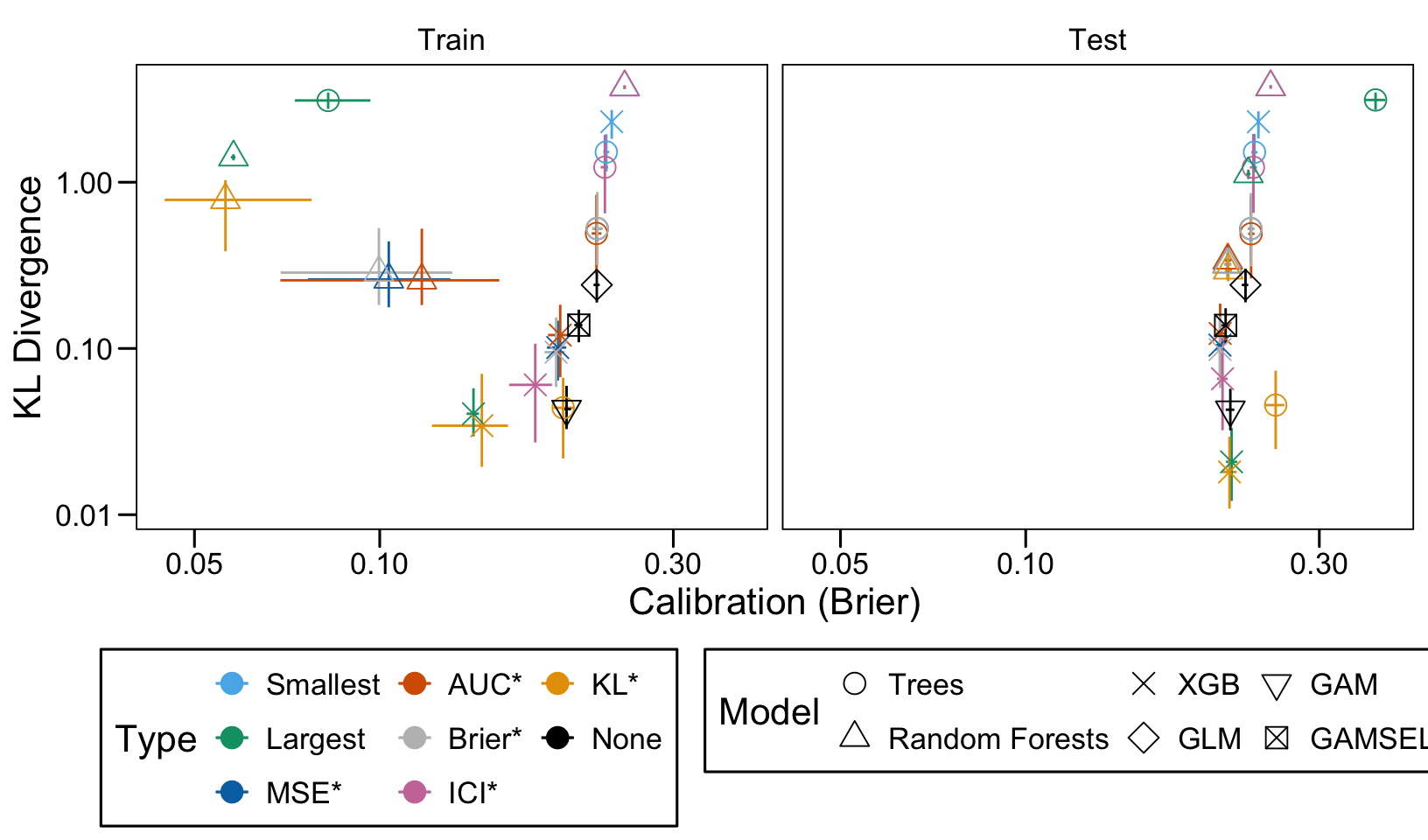
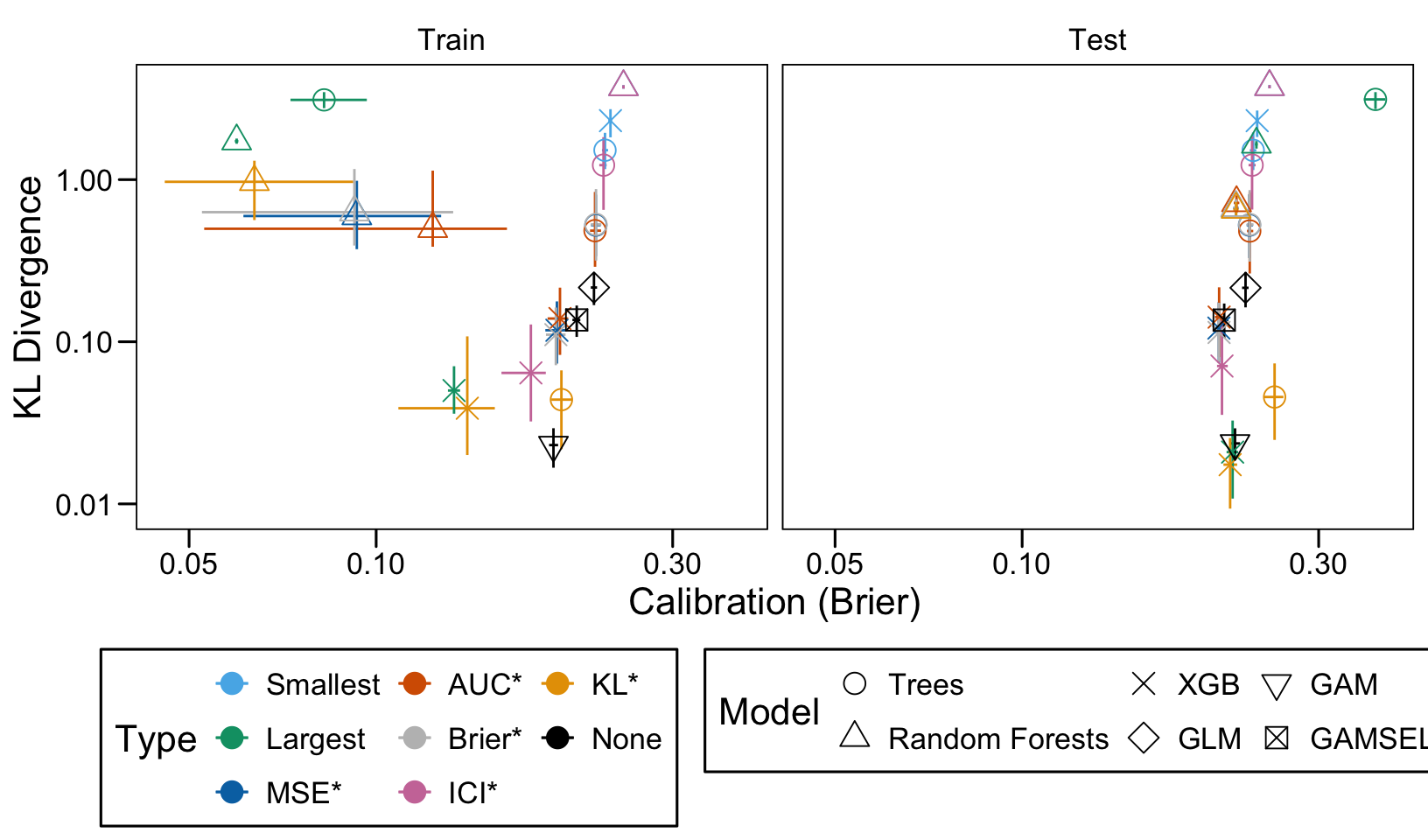
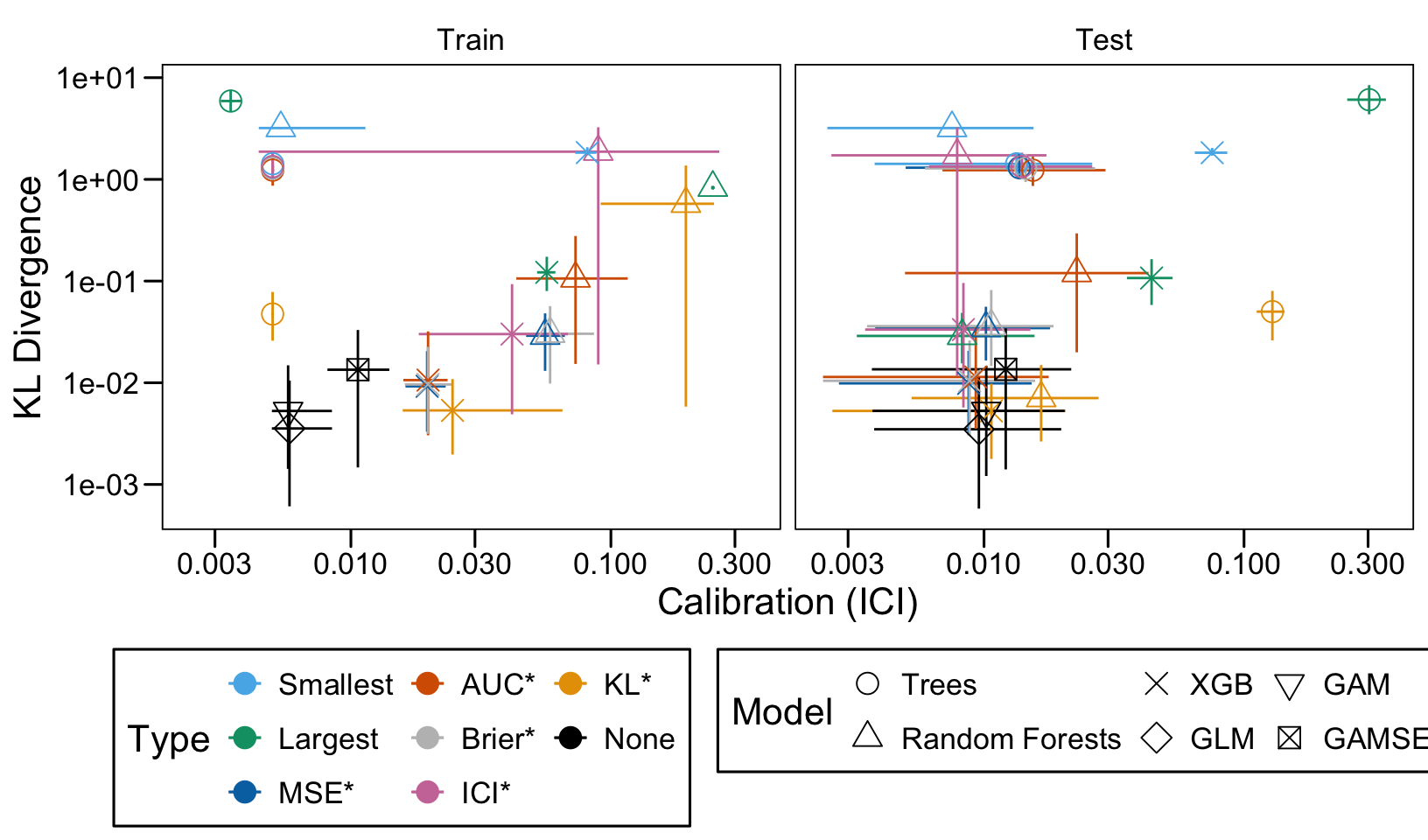
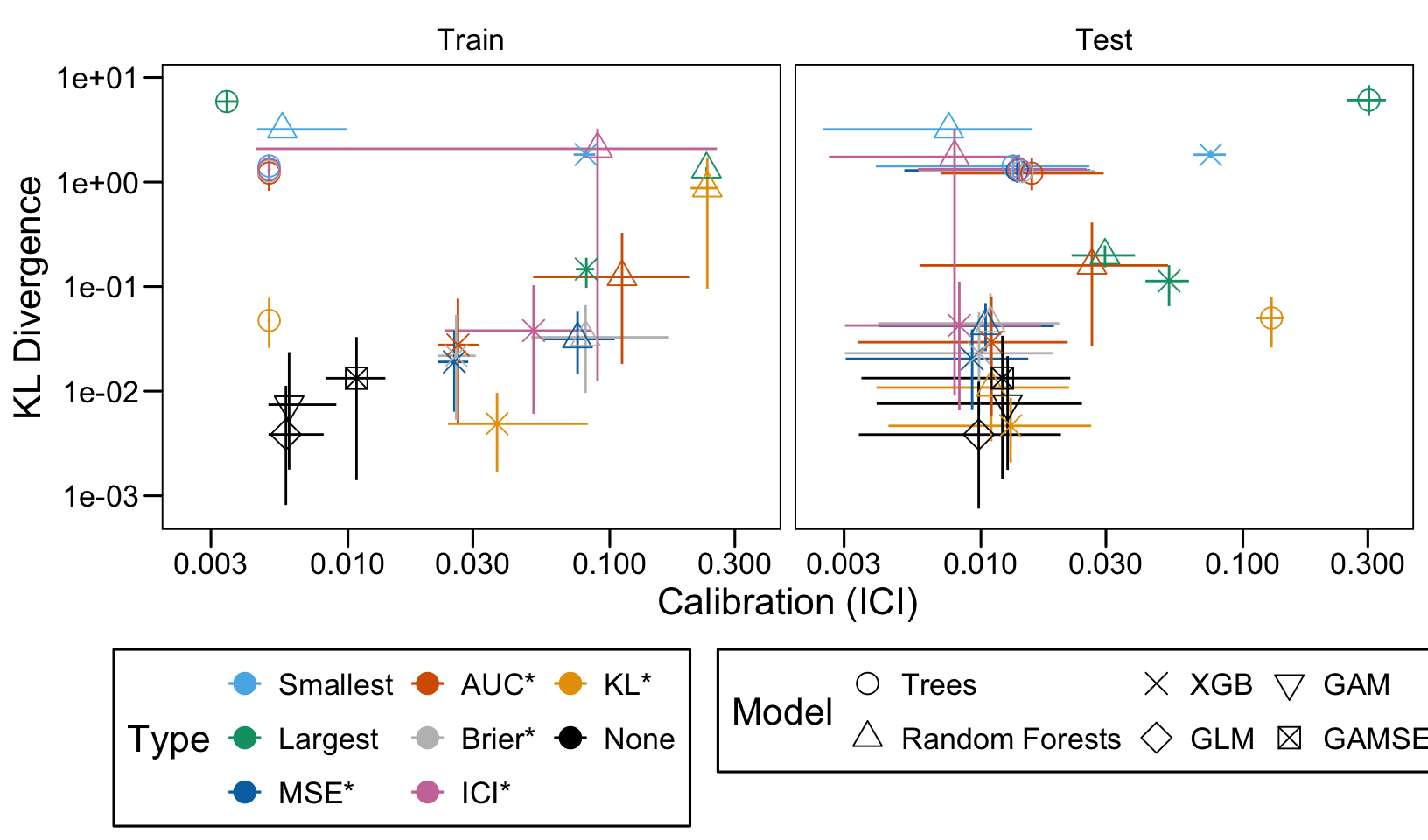
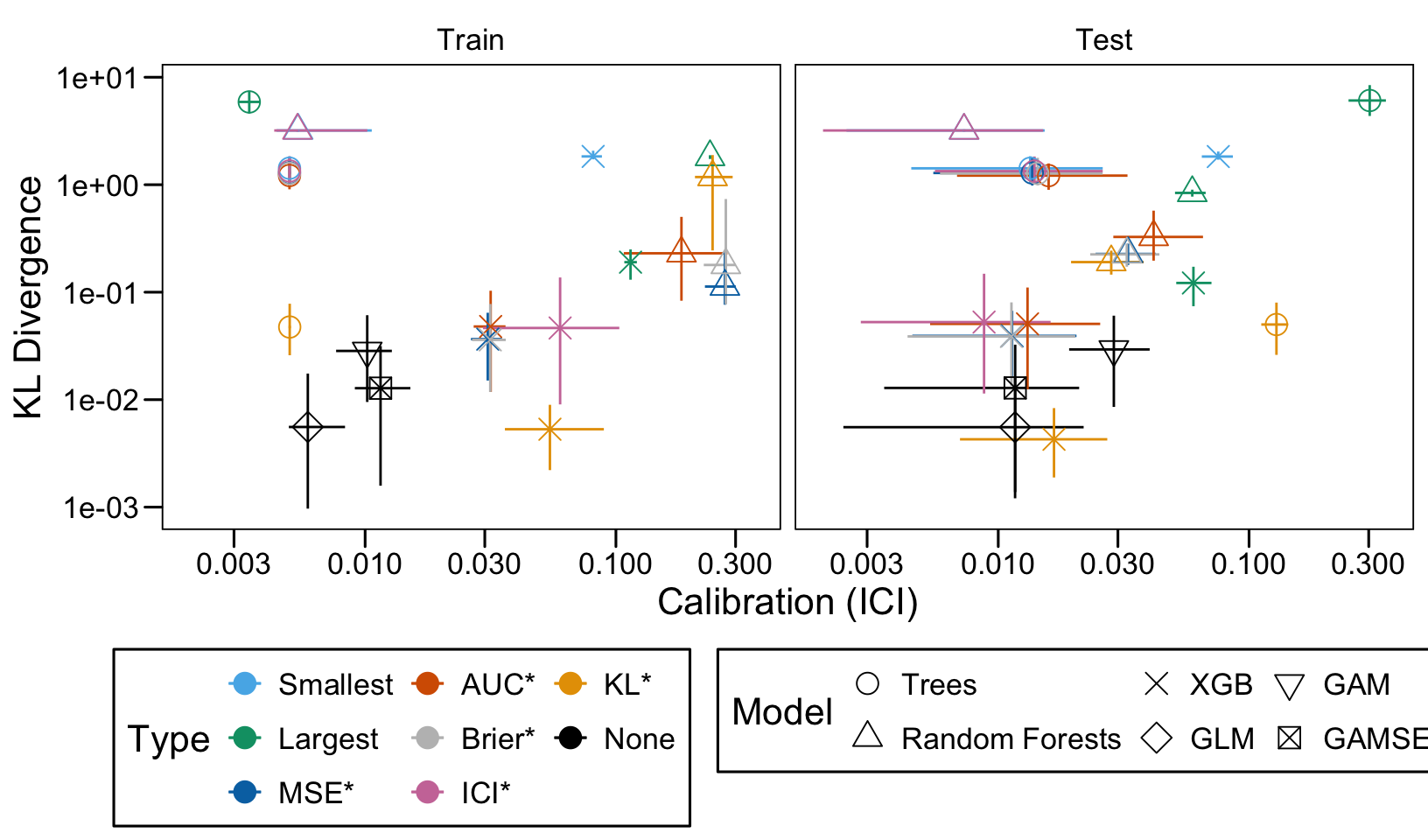
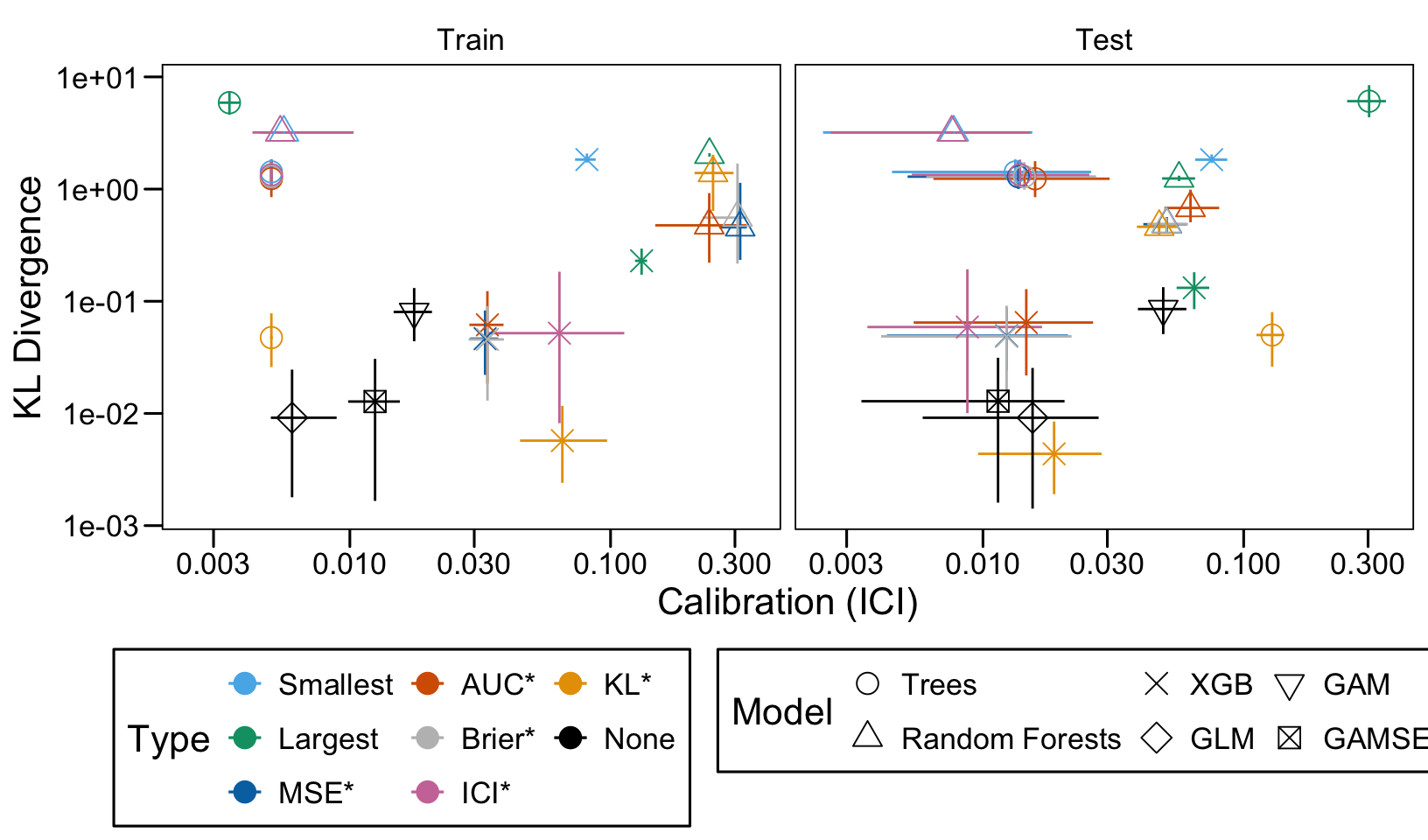
This chapter loads the estimated models from the previous chapters from this simulation part of the supplementary materials and compares them.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(locfit)
locfit 1.5-9.9 2024-03-01
Attaching package: 'locfit'
The following object is masked from 'package:purrr':
none
library(philentropy)# Colours for train/validation/testcolour_samples <-c("Train"="#0072B2","Validation"="#009E73","Test"="#D55E00")# Colour for the models of interestcolour_result_type <-c("AUC*"="#D55E00", "Smallest"="#56B4E9", "Largest"="#009E73", "Brier*"="gray","MSE*"="#0072B2","ICI*"="#CC79A7", "KL*"="#E69F00","None"="black")
definition of the theme_paper() function (for ggplot2 graphs)
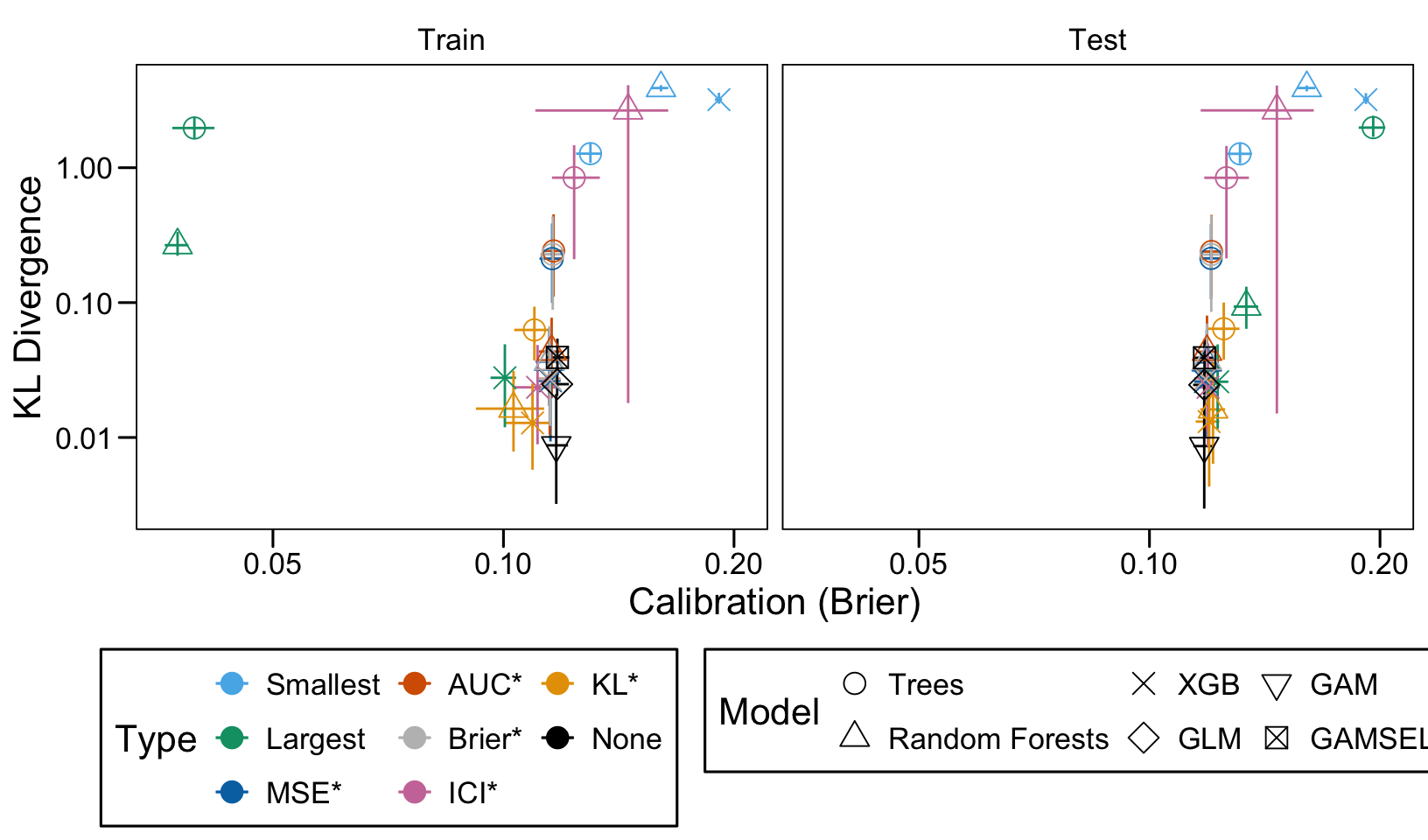
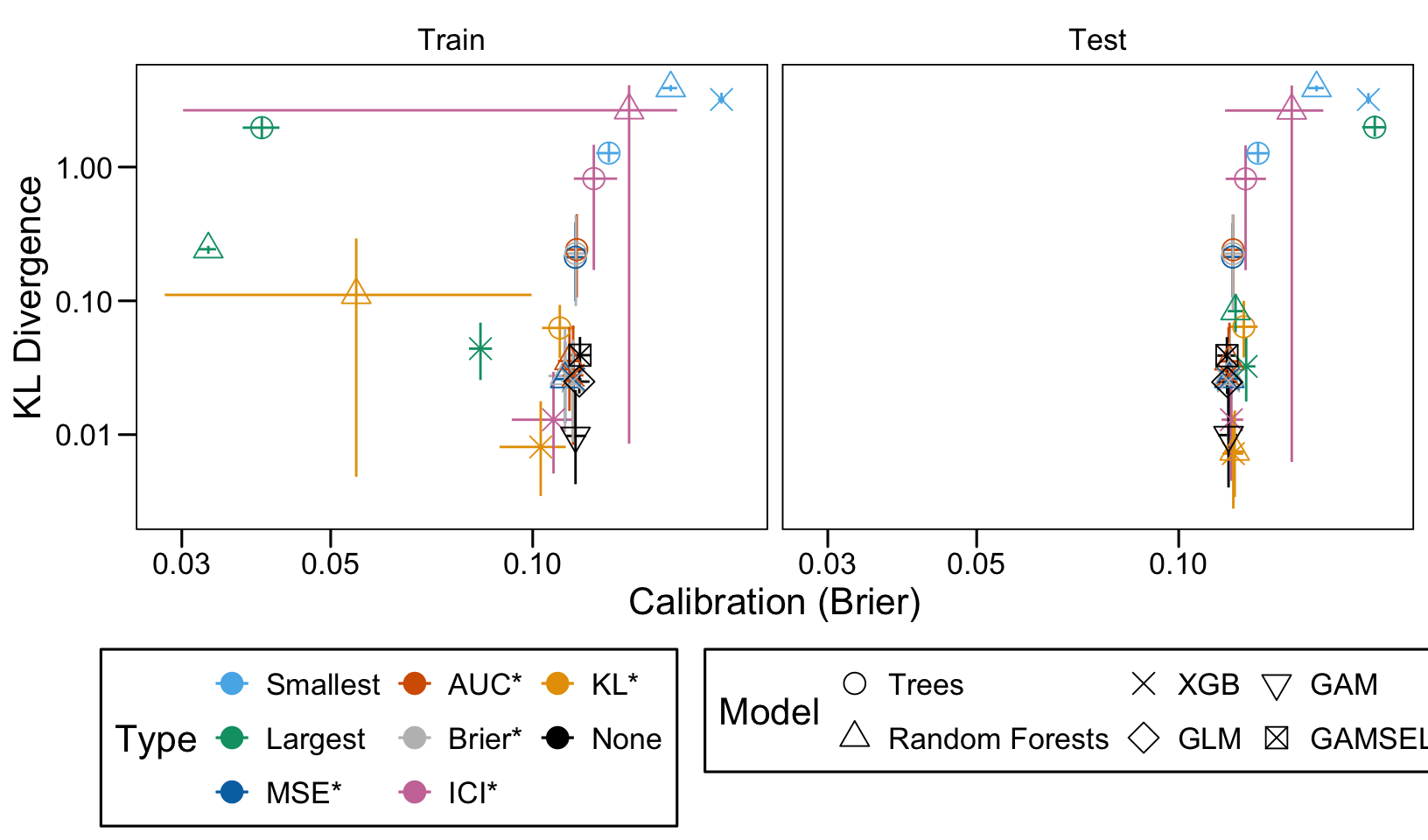
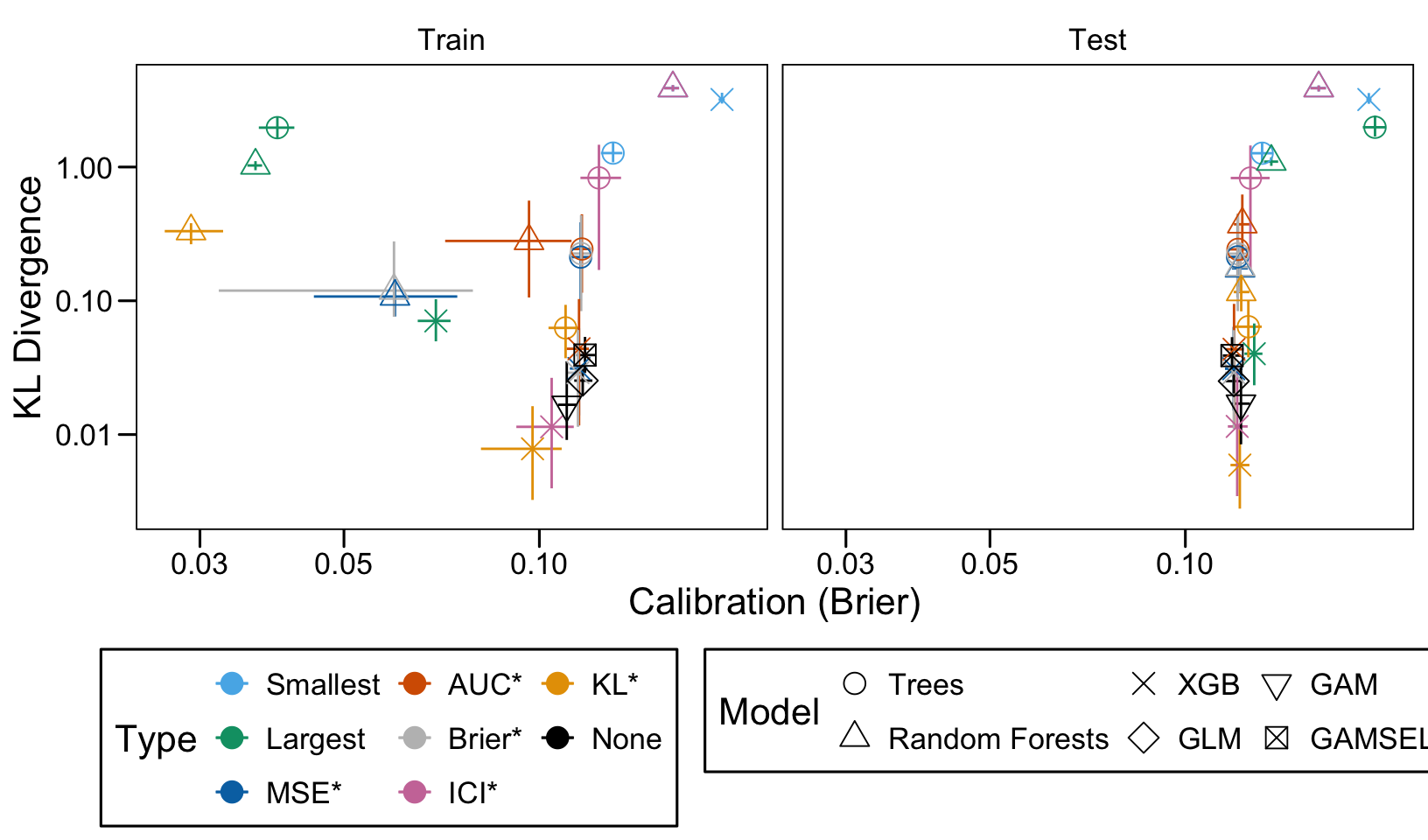
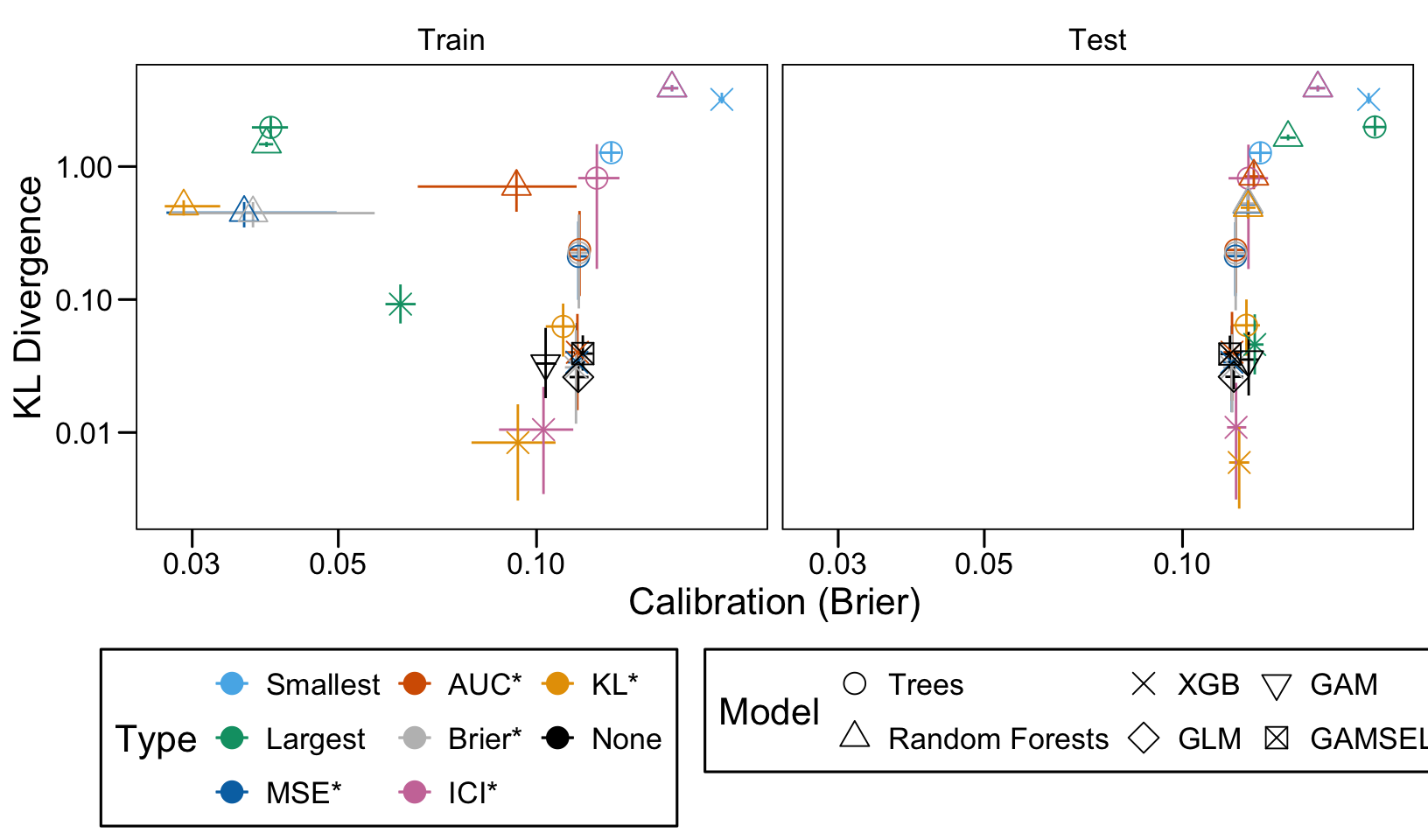
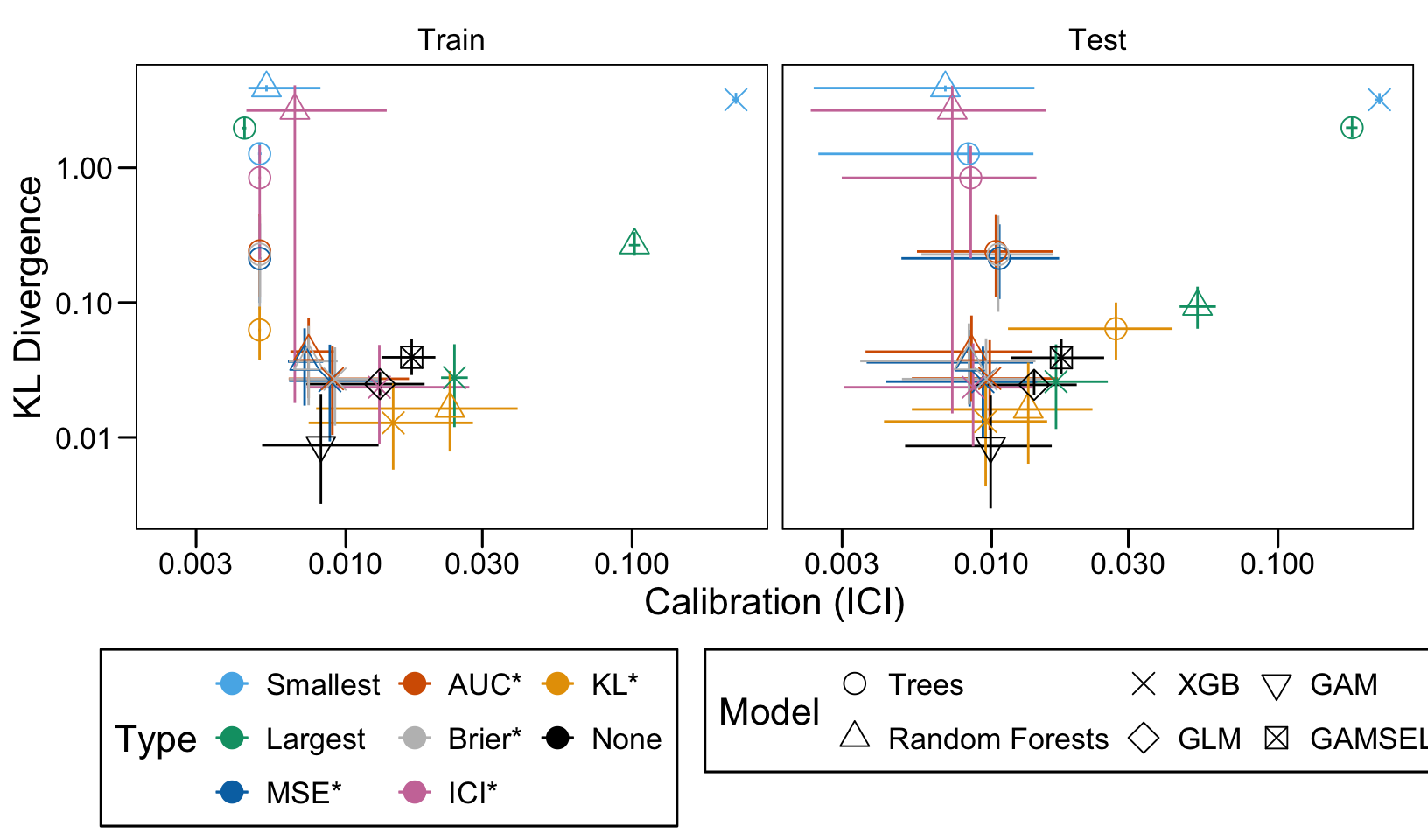
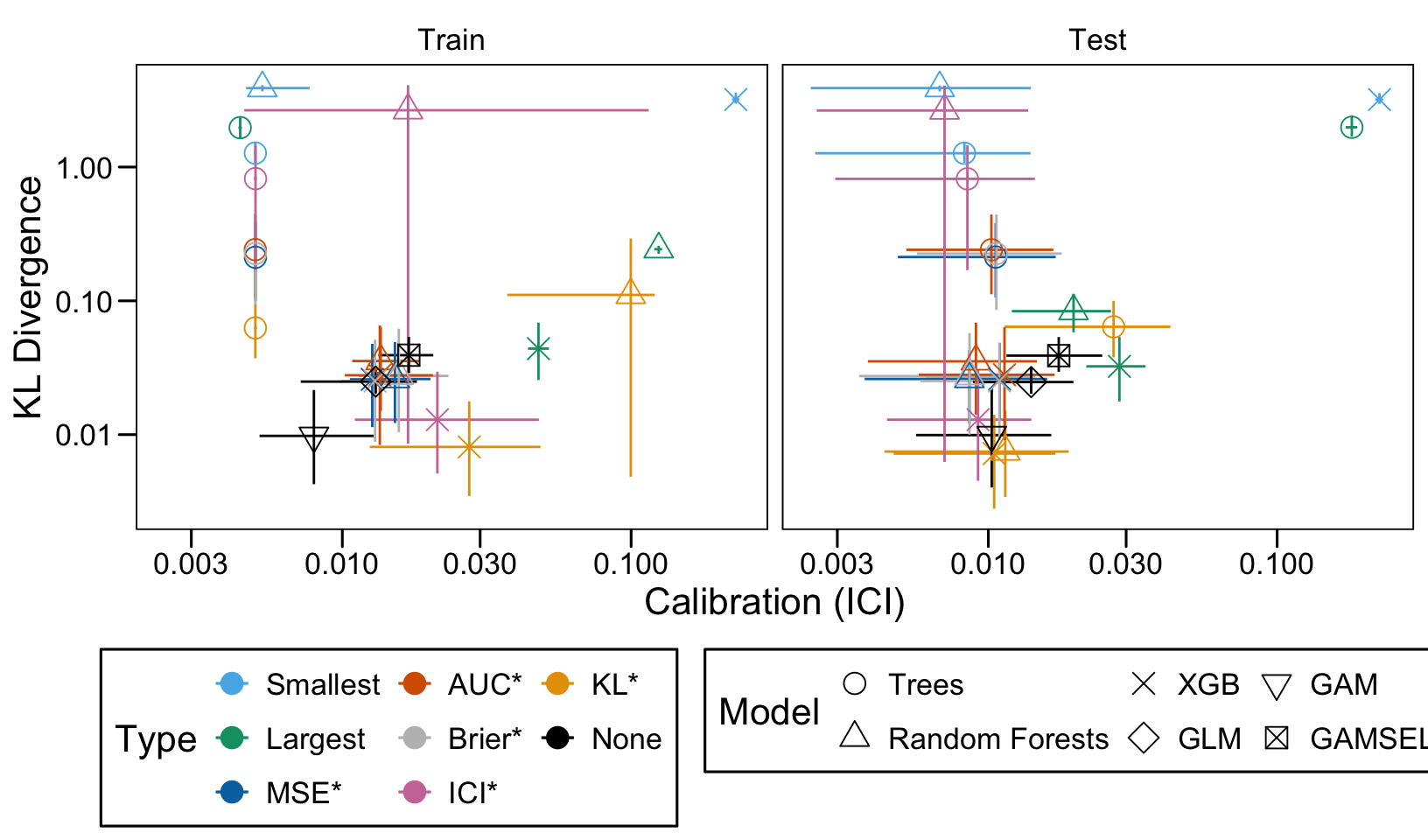
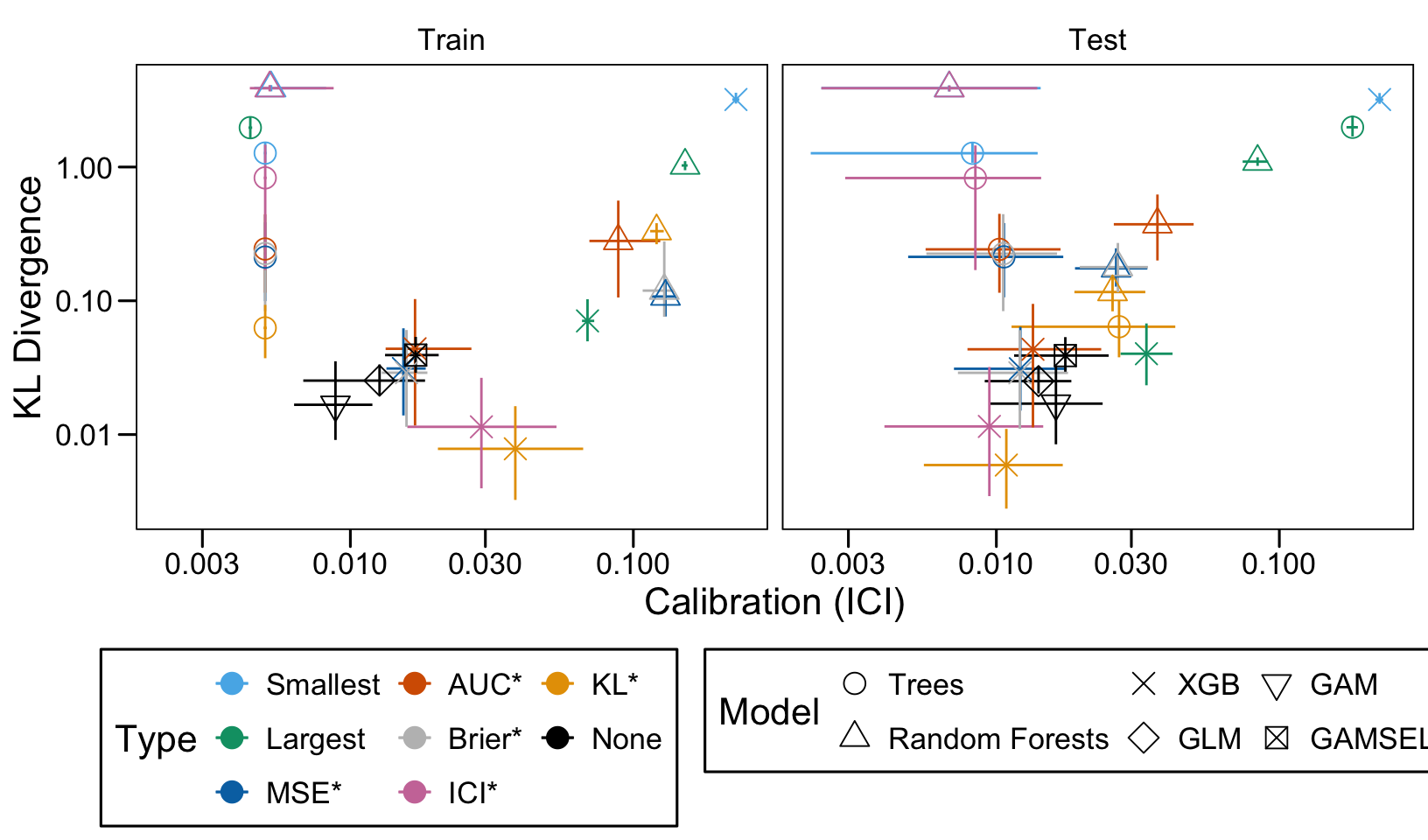
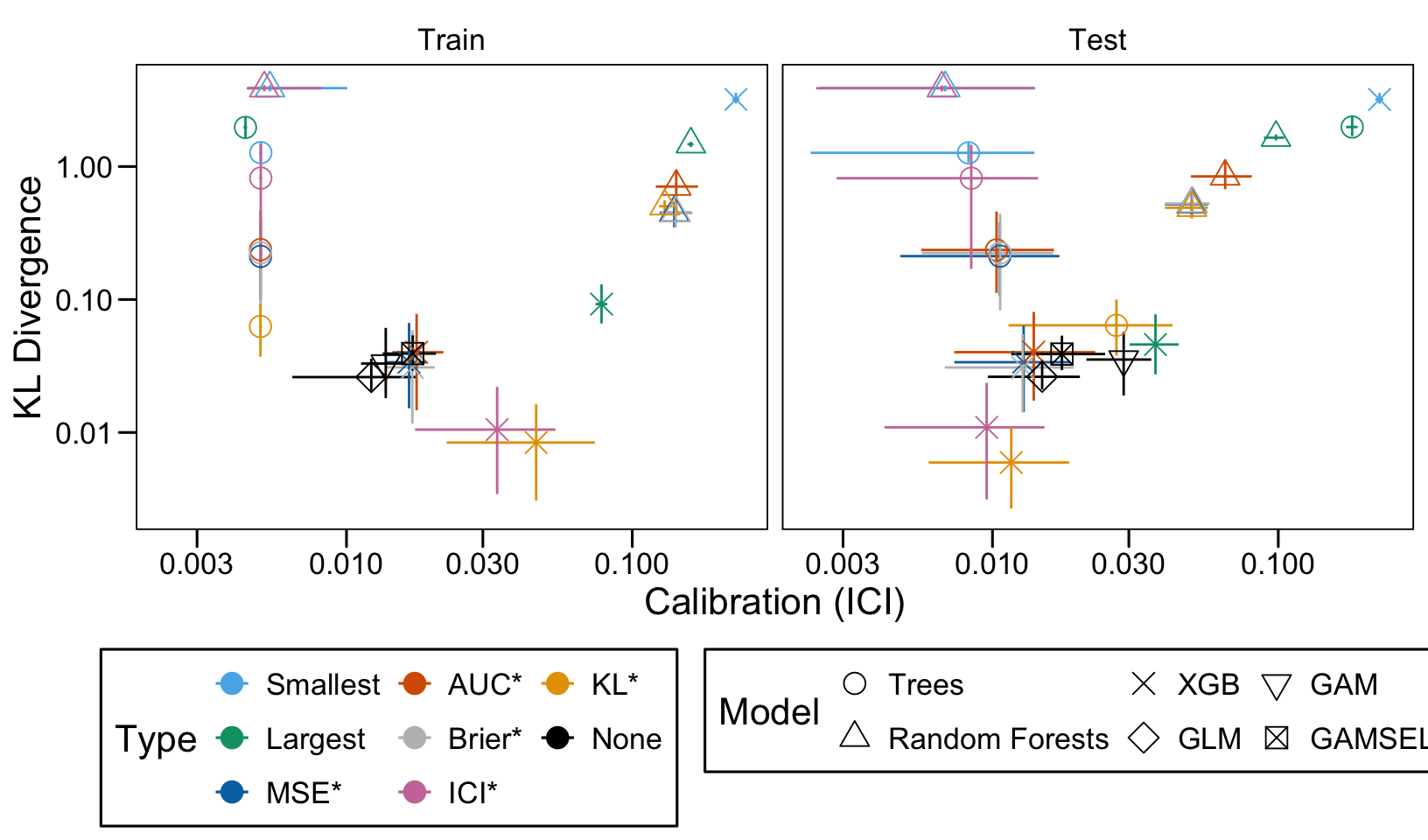
We ran 100 replications of the simulations for each scenario. Let us compute the average AUC, ICI and KL Divergence over these 100 replications, both on the train and on the validation set.
We extract the metrics from the trees of interest:
smallest: forest with the smallest average number of leaves in the trees
largest: forest with the highest average number of leaves in the trees
largest_auc: forest with the highest AUC on validation set
lowest_mse: forest with the lowest MSE on validation set
lowest_ici: forest with the lowest ICI on validation set
lowest_brier: forest with the lowest Brier score on validation set
lowest_kl: forest with the lowest KL Divergence on validation set
Code
# Identify the model with the smallest number of leaves on average on# validation setsmallest_rf <- metrics_rf_all |>filter(sample =="Validation") |>group_by(scenario, repn) |>arrange(nb_leaves) |>slice_head(n =1) |>select(scenario, repn, ind, nb_leaves) |>mutate(result_type ="smallest") |>ungroup()# Identify the largest treelargest_rf <- metrics_rf_all |>filter(sample =="Validation") |>group_by(scenario, repn) |>arrange(desc(nb_leaves)) |>slice_head(n =1) |>select(scenario, repn, ind, nb_leaves) |>mutate(result_type ="largest") |>ungroup()# Identify tree with highest AUC on test sethighest_auc_rf <- metrics_rf_all |>filter(sample =="Validation") |>group_by(scenario, repn) |>arrange(desc(AUC)) |>slice_head(n =1) |>select(scenario, repn, ind, nb_leaves) |>mutate(result_type ="largest_auc") |>ungroup()# Identify tree with lowest MSElowest_mse_rf <- metrics_rf_all |>filter(sample =="Validation") |>group_by(scenario, repn) |>arrange(mse) |>slice_head(n =1) |>select(scenario, repn, ind, nb_leaves) |>mutate(result_type ="lowest_mse") |>ungroup()# Identify tree with lowest Brierlowest_brier_rf <- metrics_rf_all |>filter(sample =="Validation") |>group_by(scenario, repn) |>arrange(brier) |>slice_head(n =1) |>select(scenario, repn, ind, nb_leaves) |>mutate(result_type ="lowest_brier") |>ungroup()# Identify tree with lowest ICIlowest_ici_rf <- metrics_rf_all |>filter(sample =="Validation") |>group_by(scenario, repn) |>arrange(ici) |>slice_head(n =1) |>select(scenario, repn, ind, nb_leaves) |>mutate(result_type ="lowest_ici") |>ungroup()# Identify tree with lowest KLlowest_kl_rf <- metrics_rf_all |>filter(sample =="Validation") |>group_by(scenario, repn) |>arrange(KL_20_true_probas) |>slice_head(n =1) |>select(scenario, repn, ind, nb_leaves) |>mutate(result_type ="lowest_kl") |>ungroup()# Merge theserf_of_interest <- smallest_rf |>bind_rows(largest_rf) |>bind_rows(highest_auc_rf) |>bind_rows(lowest_mse_rf) |>bind_rows(lowest_brier_rf) |>bind_rows(lowest_ici_rf) |>bind_rows(lowest_kl_rf)# Add metrics nowrf_of_interest <- rf_of_interest |>left_join( metrics_rf_all,by =c("scenario", "repn", "ind", "nb_leaves"),relationship ="many-to-many"# (train, valid, test) ) |>mutate(result_type =factor( result_type,levels =c("smallest", "largest", "lowest_mse", "largest_auc","lowest_brier", "lowest_ici", "lowest_kl"),labels =c("Smallest", "Largest", "MSE*", "AUC*","Brier*", "ICI*", "KL*" ) ) )# Sanity check# trees_of_interest_metrics_rf |> count(scenario, sample, result_type)
We ran 100 replications of the simulations for each scenario and each set of hyperparameters. Let us compute the average AUC, ICI and KL Divergence over these replications, both on the train and on the validation set.
Then, we compute the average values of the AUC, the ICI and the KL divergence for these models of interest over the 100 replications, for each scenario, both on the train and the validation set.
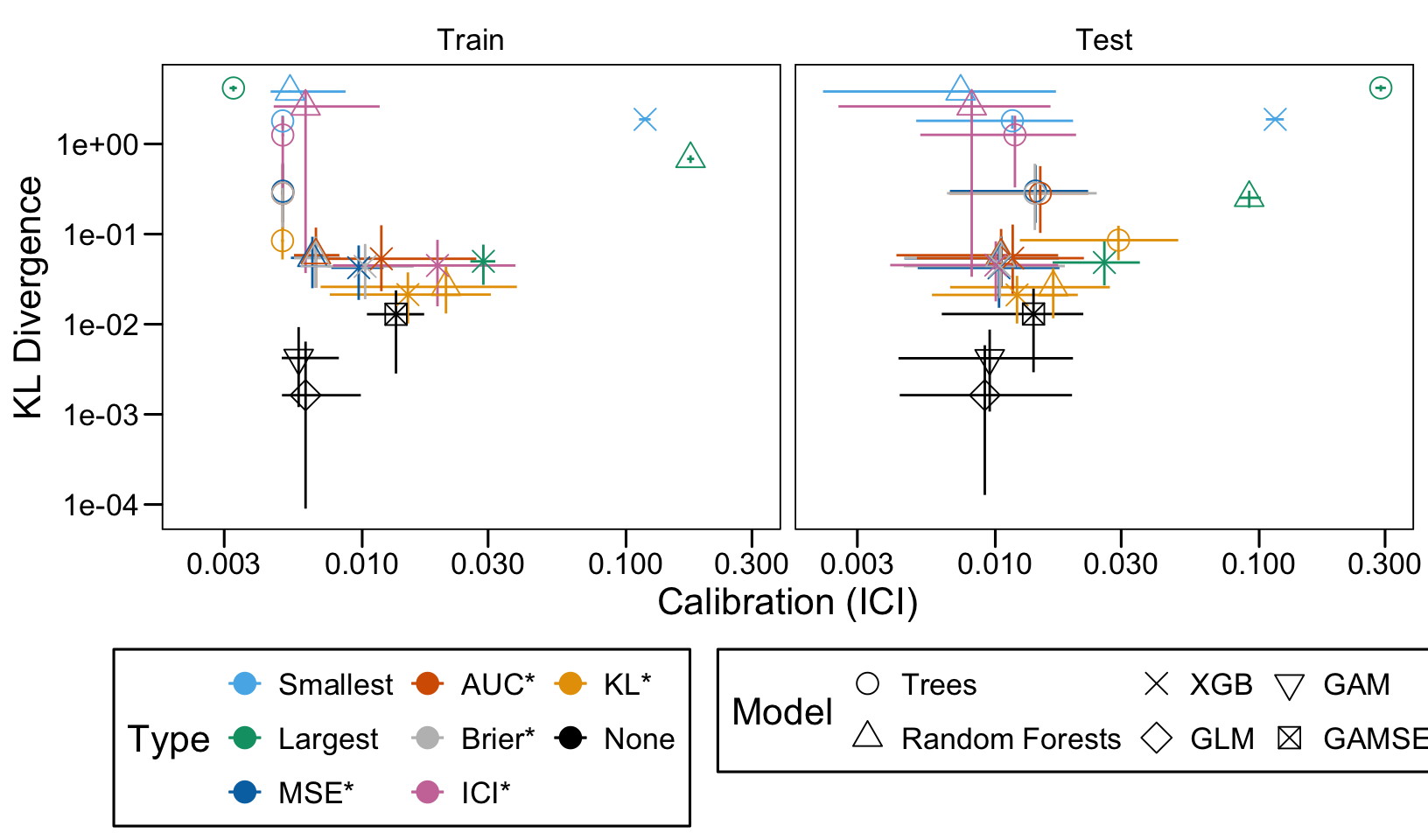
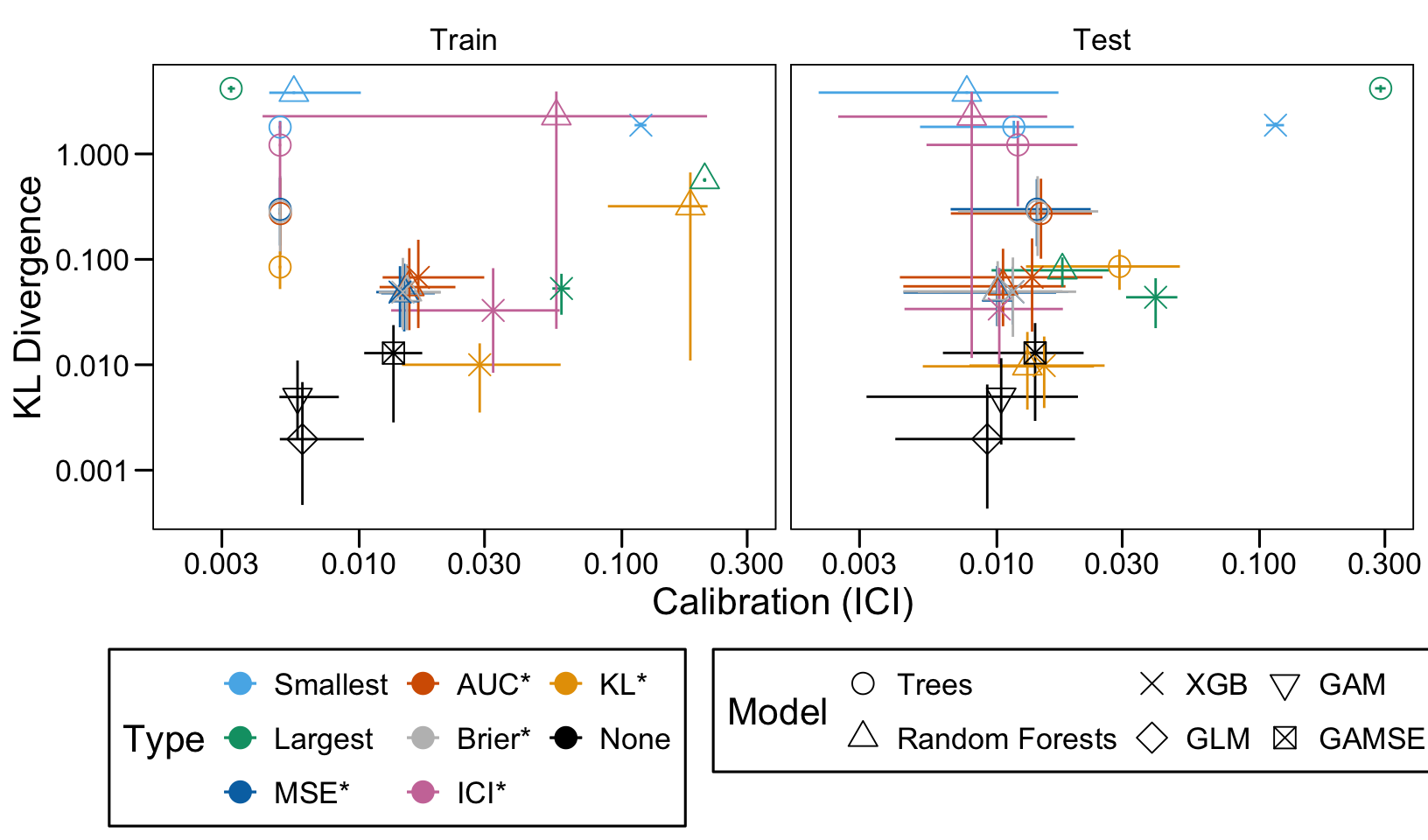
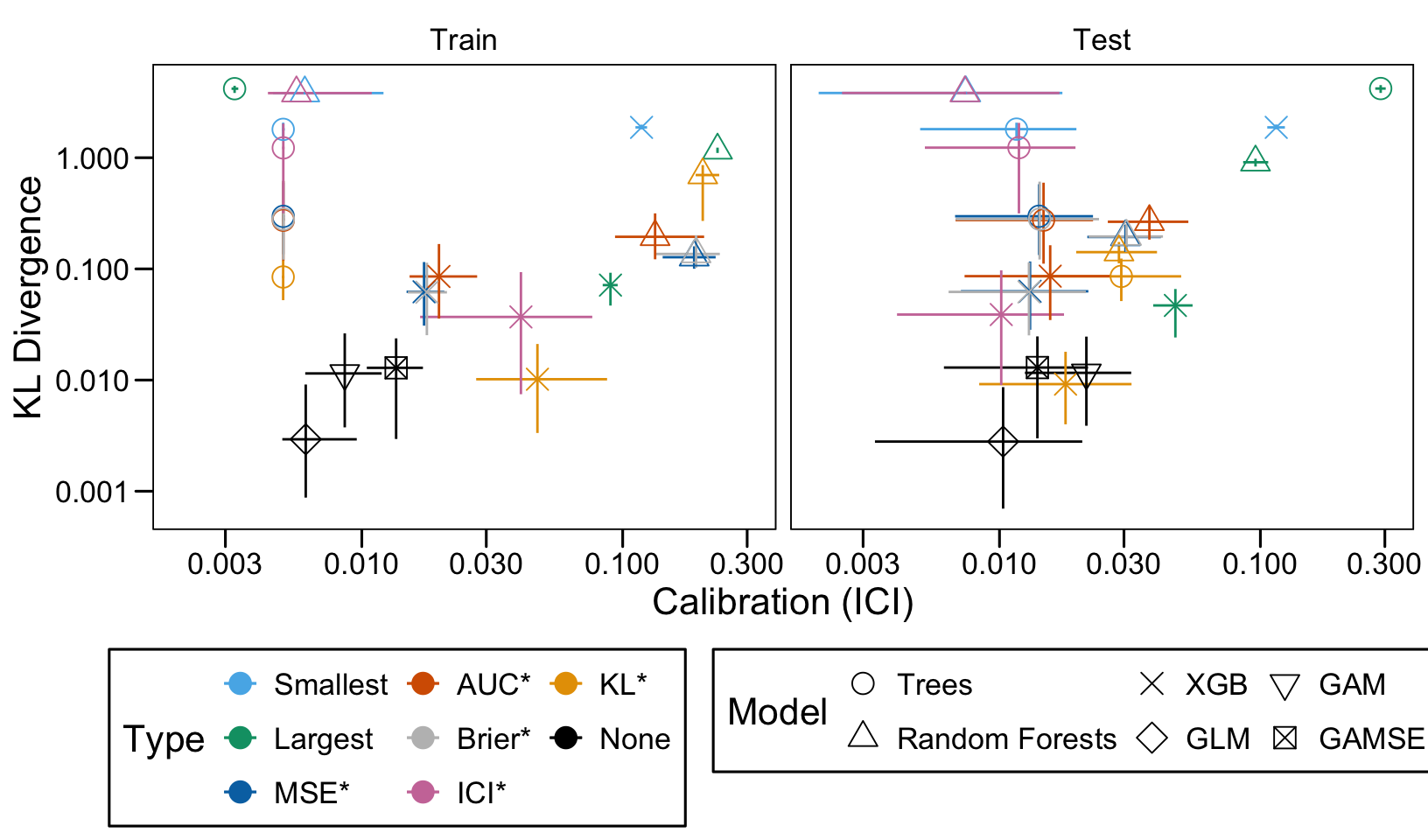
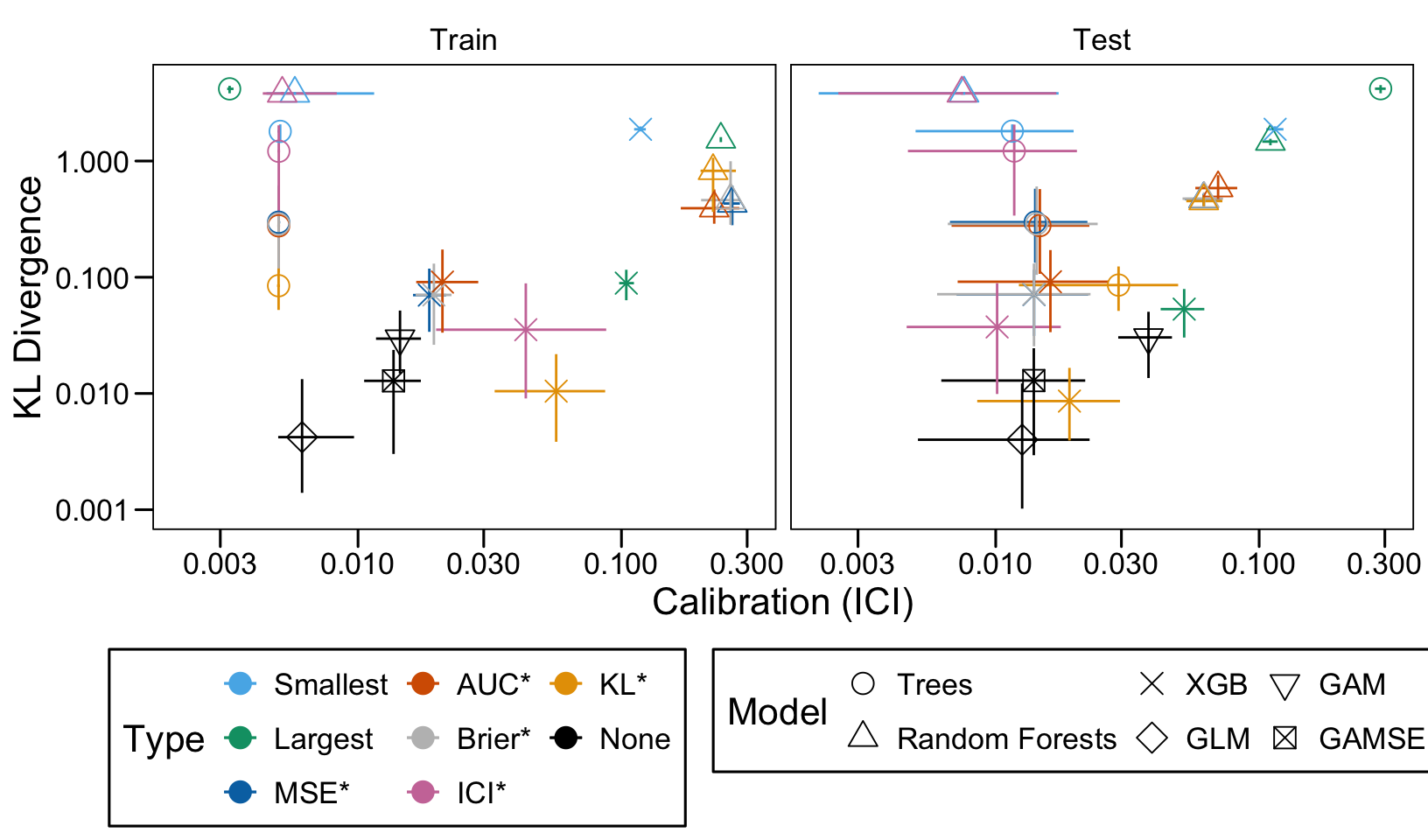
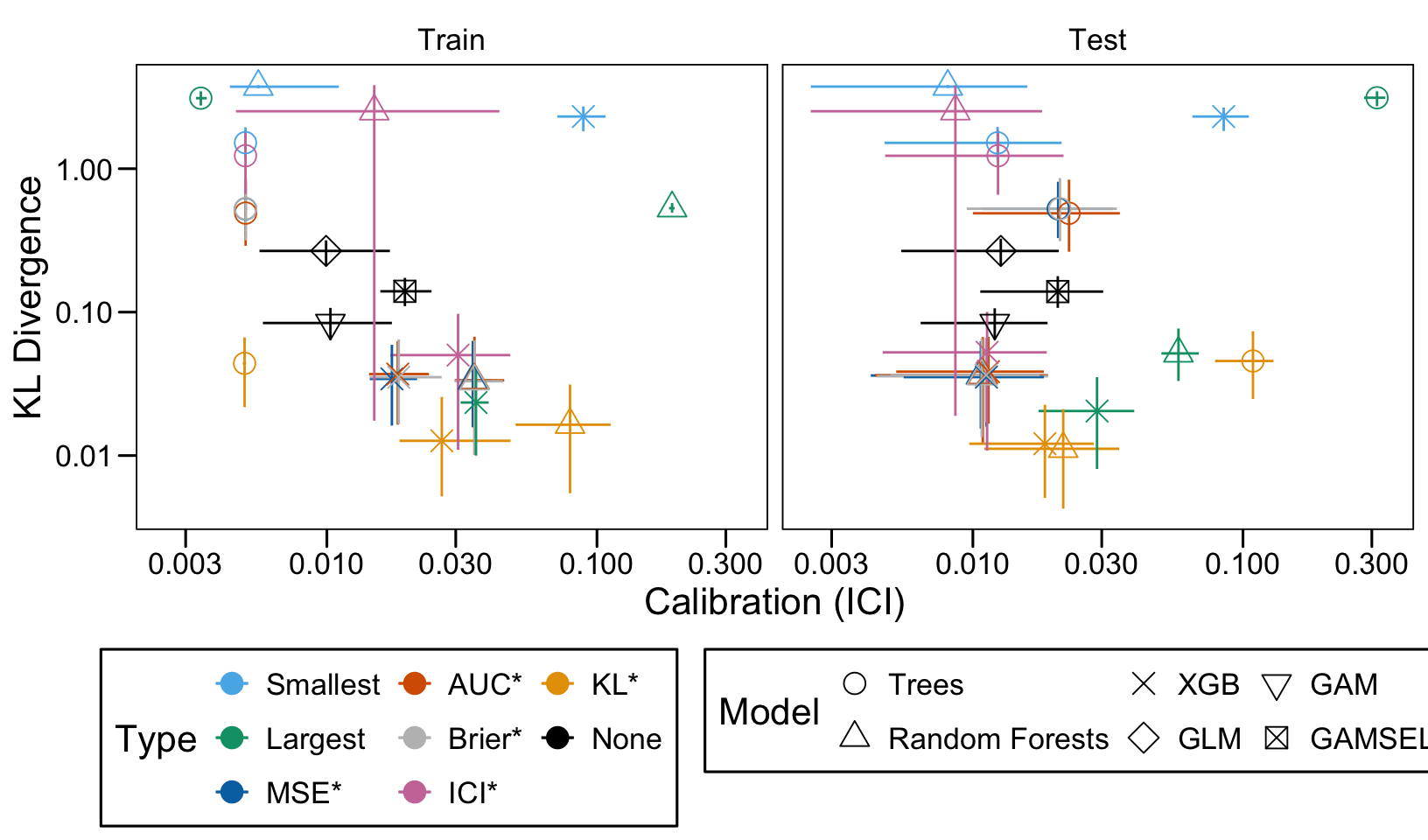
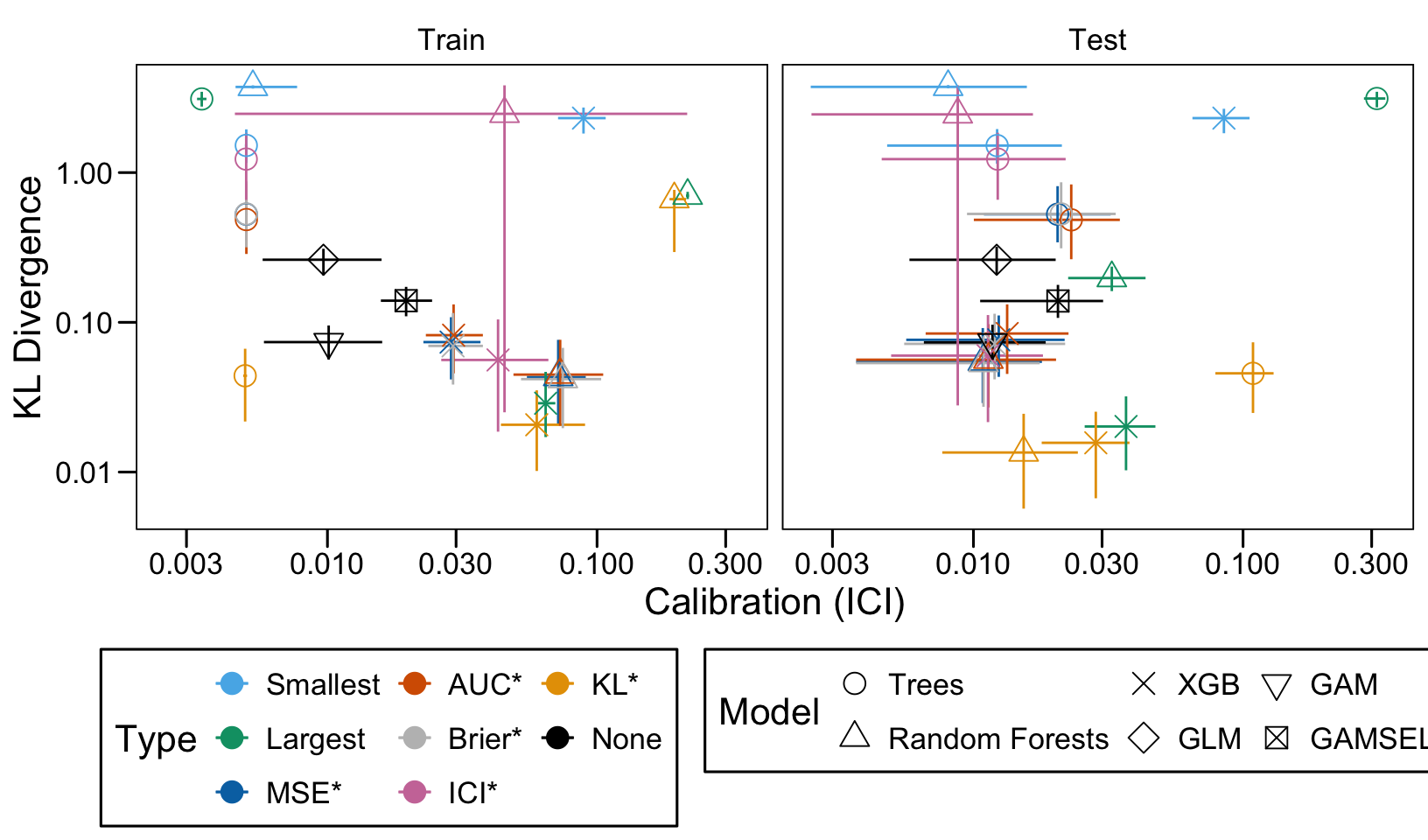
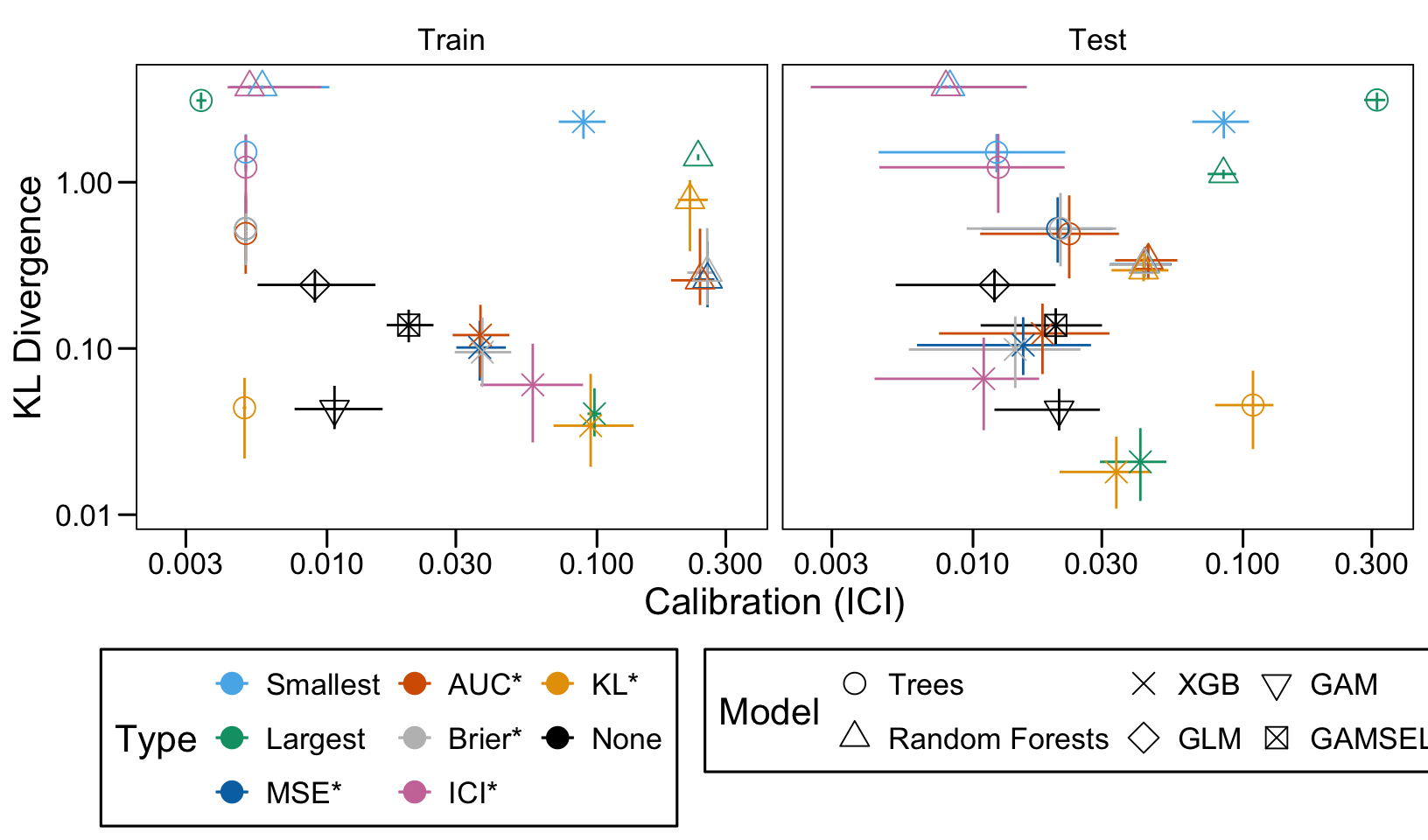
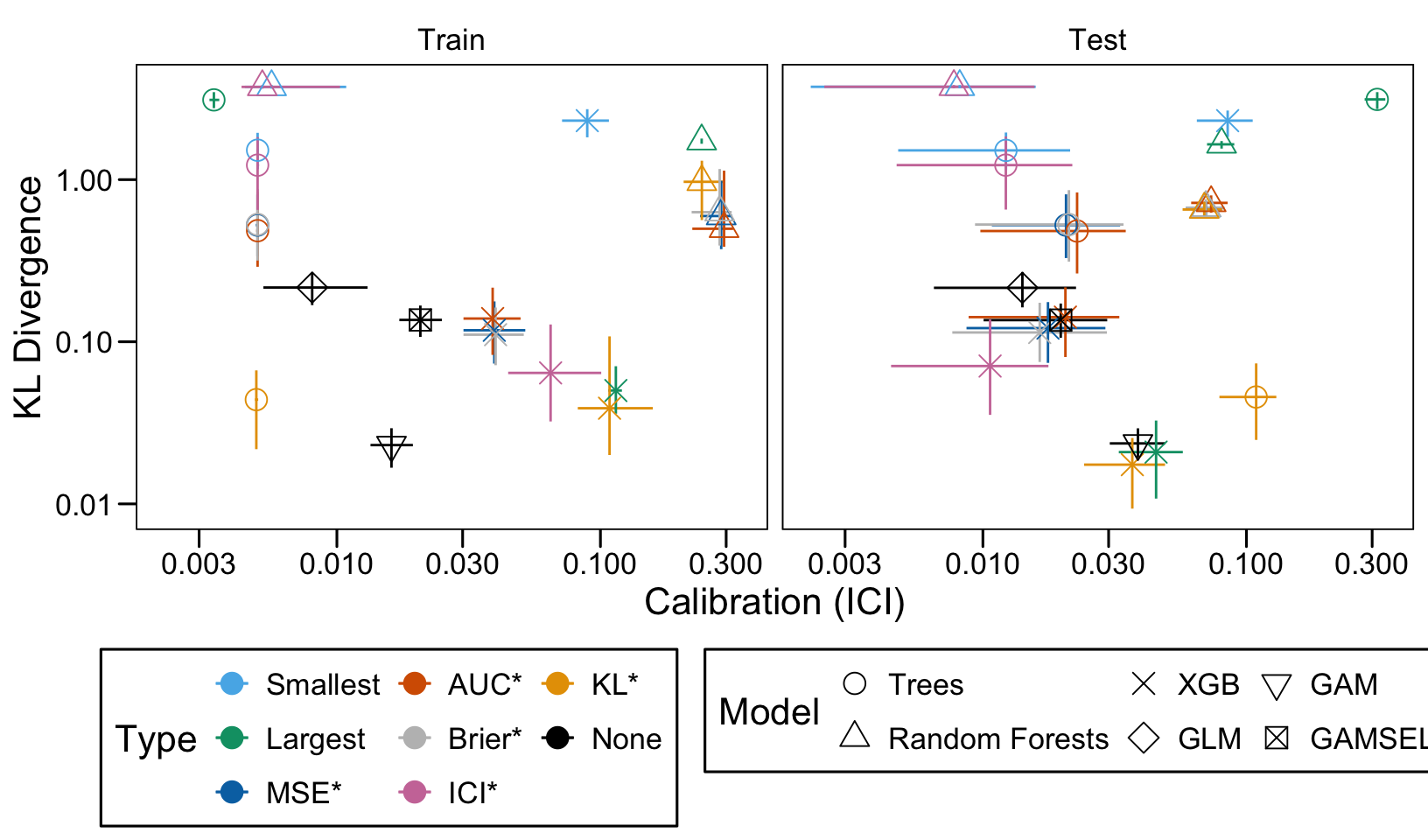
We define a function, plot_comparison() to plot the results. The left panel of the figure shows values computed on the train set, whereas the right panel shows values computed on the validation set. The shape of the dots represent the average of the metric computed over the 100 replications for the model of interest (smallest, largest, AUC*, MSE*, ICI*, KL*). The color of the points allows to identify the models of interest. Lastly, the vertical and horizontal segments show the 95% intervals computed over the 100 replications for the models of interest.
We also visualize the results in tables. For each model within a given scenario, we report the average AUC, Brier Score, ICI, and KL divergence over 100 replications for the ‘best’ model. For ensemble tree models, the ‘best’ model is identified either when maximizing the AUC (denoted \(AUC^*\)), when minimizing the Brier Score (denoted \(Brier^*\)), the ICI (denoted \(ICI^*\)), or the KL divergence (denoted \(KL^*\)). When the best model is selected based anything but the AUC, we compute the variation in the metric as the difference between the metric obtained when minimizing either the Brier score, the ICI, or the KL divergence and the metric obtained when maximizing AUC. Thus, negative values indicate a decrease in the metric compared to when the best model is selected by optimizing AUC. For general linear models, the only metrics reported are the AUC, Brier, ICI, and KL divergence.