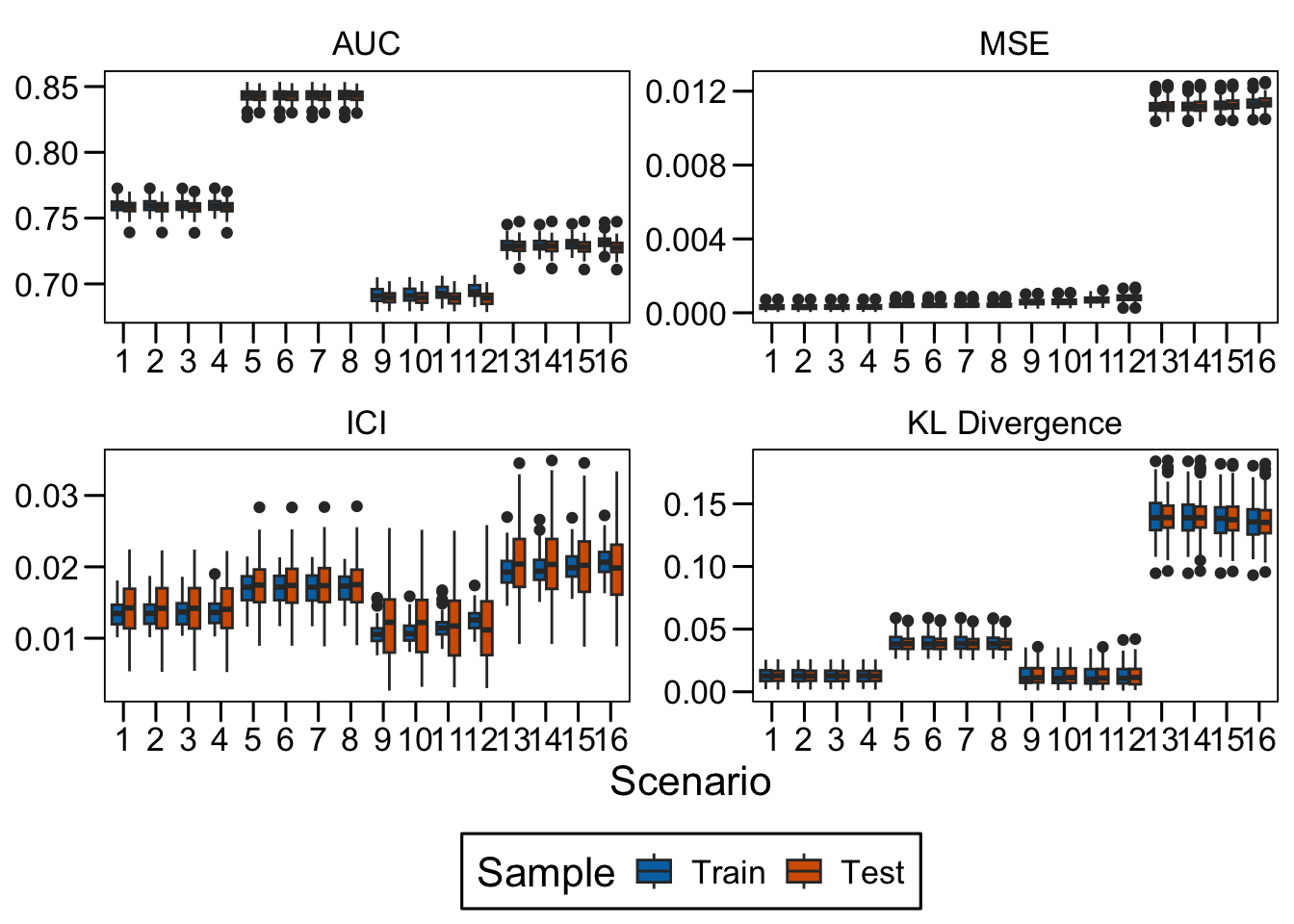
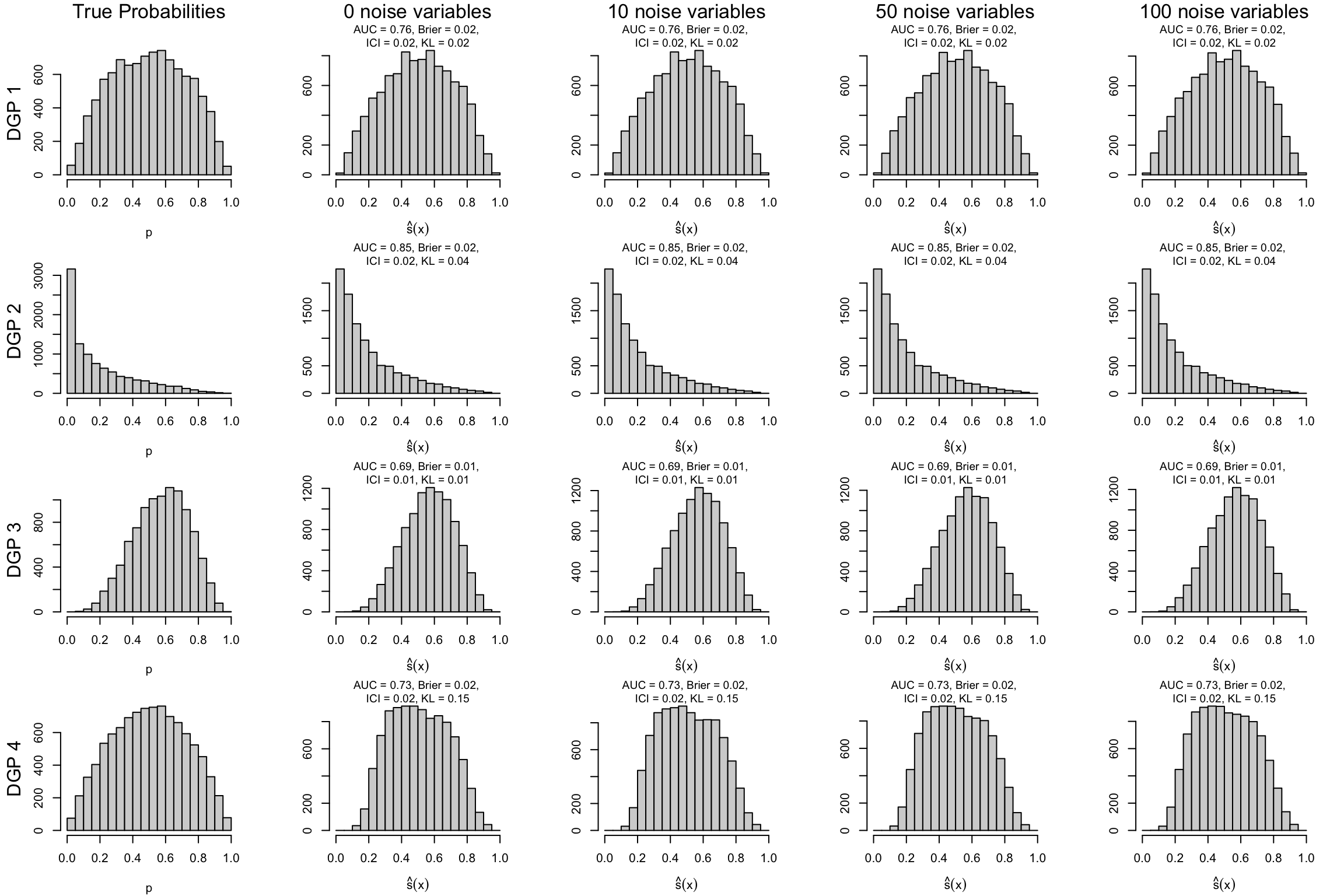
This chapter examines the scores returned by a GAMSEL (Generalized Additive Model Selection, Chouldechova and Hastie (2015)) under the different scenarios.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(gamsel)
Loaded gamsel 1.8-4
library(philentropy)library(caret) # for one hot encoding
Loading required package: lattice
Attaching package: 'caret'
The following object is masked from 'package:purrr':
lift
# Colours for train/testcolour_samples <-c("Train"="#0072B2","Test"="#D55E00")
definition of the theme_paper() function (for ggplot2 graphs)
We generate data using the first 12 scenarios from Ojeda et al. (2023) and an additional set of 4 scenarios in which the true probability does not depend on the predictors in a linear way (see Chapter 4).
When we simulate a dataset, we draw the following number of observations:
nb_obs <-10000
Definition of the 16 scenarios
# Coefficients betacoefficients <-list(# First category (baseline, 2 covariates)c(0.5, 1), # scenario 1, 0 noise variablec(0.5, 1), # scenario 2, 10 noise variablesc(0.5, 1), # scenario 3, 50 noise variablesc(0.5, 1), # scenario 4, 100 noise variables# Second category (same as baseline, with lower number of 1s)c(0.5, 1), # scenario 5, 0 noise variablec(0.5, 1), # scenario 6, 10 noise variablesc(0.5, 1), # scenario 7, 50 noise variablesc(0.5, 1), # scenario 8, 100 noise variables# Third category (same as baseline but with 5 num. and 5 categ. covariates)c(0.1, 0.2, 0.3, 0.4, 0.5, 0.01, 0.02, 0.03, 0.04, 0.05),c(0.1, 0.2, 0.3, 0.4, 0.5, 0.01, 0.02, 0.03, 0.04, 0.05),c(0.1, 0.2, 0.3, 0.4, 0.5, 0.01, 0.02, 0.03, 0.04, 0.05),c(0.1, 0.2, 0.3, 0.4, 0.5, 0.01, 0.02, 0.03, 0.04, 0.05),# Fourth category (nonlinear predictor, 3 covariates)c(0.5, 1, .3), # scenario 5, 0 noise variablec(0.5, 1, .3), # scenario 6, 10 noise variablesc(0.5, 1, .3), # scenario 7, 50 noise variablesc(0.5, 1, .3) # scenario 8, 100 noise variables)# Mean parameter for the normal distribution to draw from to draw num covariatesmean_num <-list(# First category (baseline, 2 covariates)rep(0, 2), # scenario 1, 0 noise variablerep(0, 2), # scenario 2, 10 noise variablesrep(0, 2), # scenario 3, 50 noise variablesrep(0, 2), # scenario 4, 100 noise variables# Second category (same as baseline, with lower number of 1s)rep(0, 2), # scenario 5, 0 noise variablerep(0, 2), # scenario 6, 10 noise variablesrep(0, 2), # scenario 7, 50 noise variablesrep(0, 2), # scenario 8, 100 noise variables# Third category (same as baseline but with 5 num. and 5 categ. covariates)rep(0, 5),rep(0, 5),rep(0, 5),rep(0, 5),# Fourth category (nonlinear predictor, 3 covariates)rep(0, 3),rep(0, 3),rep(0, 3),rep(0, 3))# Sd parameter for the normal distribution to draw from to draw num covariatessd_num <-list(# First category (baseline, 2 covariates)rep(1, 2), # scenario 1, 0 noise variablerep(1, 2), # scenario 2, 10 noise variablesrep(1, 2), # scenario 3, 50 noise variablesrep(1, 2), # scenario 4, 100 noise variables# Second category (same as baseline, with lower number of 1s)rep(1, 2), # scenario 5, 0 noise variablerep(1, 2), # scenario 6, 10 noise variablesrep(1, 2), # scenario 7, 50 noise variablesrep(1, 2), # scenario 8, 100 noise variables# Third category (same as baseline but with 5 num. and 5 categ. covariates)rep(1, 5),rep(1, 5),rep(1, 5),rep(1, 5),# Fourth category (nonlinear predictor, 3 covariates)rep(1, 3),rep(1, 3),rep(1, 3),rep(1, 3))params_df <-tibble(scenario =1:16,coefficients = coefficients,n_num =c(rep(2, 8), rep(5, 4), rep(3, 4)),add_categ =c(rep(FALSE, 8), rep(TRUE, 4), rep(FALSE, 4)),n_noise =rep(c(0, 10, 50, 100), 4),mean_num = mean_num,sd_num = sd_num,size_train =rep(nb_obs, 16),size_test =rep(nb_obs, 16),transform_probs =c(rep(FALSE, 4), rep(TRUE, 4), rep(FALSE, 4), rep(FALSE, 4)),linear_predictor =c(rep(TRUE, 12), rep(FALSE, 4)),seed =202105)rm(coefficients, mean_num, sd_num)
11.2 Metrics
We load the functions from Chapter 3 to compute performance, calibration and divergence metrics.
source("functions/metrics.R")
11.3 Simulations Setup
As in previous chapters, we define a function to run replications of the simulations for each scenario. This function is called simul_gamsel(). It uses multiple helper functions also defined here.
Helper Functions
#' Counts the number of scores in each of the 20 equal-sized bins over [0,1]#'#' @param scores_train vector of scores on the train test#' @param scores_test vector of scores on the test testget_histogram <-function(scores_train, scores_test) { breaks <-seq(0, 1, by = .05) scores_train_hist <-hist(scores_train, breaks = breaks, plot =FALSE) scores_test_hist <-hist(scores_test, breaks = breaks, plot =FALSE) scores_hist <-list(train = scores_train_hist,test = scores_test_hist ) scores_hist}#' Get KL divergence metrics for estimated scores and true probabilities#' #' @param scores_train vector of scores on the train test#' @param scores_test vector of scores on the test test#' @param true_prob list of true probabilities on train and test setget_disp_metrics <-function(scores_train, scores_test, true_prob) { disp_train <-dispersion_metrics(true_probas = true_prob$train, scores = scores_train ) |>mutate(sample ="train") disp_test <-dispersion_metrics(true_probas = true_prob$test, scores = scores_test ) |>mutate(sample ="test") tb_disp_metrics <- disp_train |>bind_rows(disp_test) tb_disp_metrics}#' Get the performance and calibration metrics for estimated scores#' #' @param scores_train vector of scores on the train test#' @param scores_test vector of scores on the test test#' @param tb_train train set#' @param tb_test test set#' @param true_prob list of true probabilities on train and test setget_perf_metrics <-function(scores_train, scores_test, tb_train, tb_test, true_prob) {# We add very small noise to predicted scores# otherwise the local regression may crash scores_train_noise <- scores_train +runif(n =length(scores_train), min =0, max =0.01) scores_train_noise[scores_train_noise >1] <-1 metrics_train <-compute_metrics(obs = tb_train$d, scores = scores_train_noise, true_probas = true_prob$train ) |>mutate(sample ="train") scores_test_noise <- scores_test +runif(n =length(scores_test), min =0, max =0.01) scores_test_noise[scores_test_noise >1] <-1 metrics_test <-compute_metrics(obs = tb_test$d, scores = scores_test_noise, true_probas = true_prob$test ) |>mutate(sample ="test") tb_metrics <- metrics_train |>bind_rows(metrics_test) tb_metrics}#' Estimation of P(q1 < score < q2)#' #' @param scores_train vector of scores on the train test#' @param scores_test vector of scores on the test test#' @param q1 vector of desired values for q1 (q2 = 1-q1)estim_prop <-function(scores_train, scores_test, q1 =c(.1, .2, .3, .4)) { proq_scores_train <-map( q1,~prop_btw_quantiles(s = scores_train, q1 = .x) ) |>list_rbind() |>mutate(sample ="train") proq_scores_test <-map( q1,~prop_btw_quantiles(s = scores_test, q1 = .x) ) |>list_rbind() |>mutate(sample ="test") proq_scores_train |>bind_rows(proq_scores_test)}
The simul_gamsel() function
#' Run a single replication of the simulations of a scenario#' Fits a GAMSEL model to the data.#' #' @param scenario ID of the scenario#' @param params_df tibble with the parameters used to generate data#' @param repn replication ID numbersimul_gamsel <-function(scenario, params_df, repn) {# Generate Data---- simu_data <-simulate_data_wrapper(scenario = scenario,params_df = params_df,repn = repn ) tb_train <- simu_data$data$train |>rename(d = y) tb_test <- simu_data$data$test |>rename(d = y) true_prob <-list(train = simu_data$data$probs_train,test = simu_data$data$probs_test )# Format Data----if (scenario %in%9:12) {# Factor variables tb_train <- tb_train |>mutate(across(x6:x10, as.factor)) tb_test <- tb_test |>mutate(across(x6:x10, as.factor)) } X_train <- tb_train |>select(-d) X_test <- tb_test |>select(-d) y_train <- tb_train |>pull(d)## One hot encoding dmy_train <-dummyVars(" ~ -1+.", data = X_train, fullRank =TRUE, contrasts =TRUE, sep ="." ) X_dmy_train <-data.frame(predict(dmy_train, newdata = X_train))# using same encoder for test set X_dmy_test <-data.frame(predict(dmy_train, newdata = X_test)) categ_names <-map2(.x = dmy_train$facVars, .y = dmy_train$lvls, .f =~str_c(.x, ".", .y) ) |>unlist()# Estimation----## Degrees deg <-ifelse(!colnames(X_dmy_train) %in% categ_names, 5, 1) gamsel_cv <-cv.gamsel(x = X_dmy_train, y = y_train, family="binomial", degrees = deg ) gamsel_out <-gamsel(x = X_dmy_train, y = y_train, family ="binomial", degrees = deg,lambda = gamsel_cv$lambda.min )# Predicted scores---- scores_train <-predict( gamsel_out, newdata = X_dmy_train, type ="response")[, 1] scores_test <-predict( gamsel_out, newdata = X_dmy_test, type ="response")[, 1]# Histogram of scores---- scores_hist <-get_histogram(scores_train, scores_test)# Performance and Calibration Metrics---- tb_metrics <-get_perf_metrics(scores_train = scores_train,scores_test = scores_test,tb_train = tb_train,tb_test = tb_test,true_prob = true_prob) |>mutate(scenario = simu_data$scenario,repn = simu_data$repn )# Dispersion Metrics---- tb_disp_metrics <-get_disp_metrics(scores_train = scores_train,scores_test = scores_test,true_prob = true_prob ) |>mutate(scenario = simu_data$scenario,repn = simu_data$repn ) metrics <-suppressMessages(left_join(tb_metrics, tb_disp_metrics) )# Estimation of P(q1 < score < q2)---- tb_prop_scores <-estim_prop(scores_train, scores_test) |>mutate(scenario = simu_data$scenario,repn = simu_data$repn )list(scenario = simu_data$scenario, # data scenariorepn = simu_data$repn, # data replication IDmetrics = metrics, # table with performance/calib/divergencetb_prop_scores = tb_prop_scores, # table with P(q1 < score < q2)scores_hist = scores_hist # histogram of scores )}
The desired number of replications for each scenario needs to be set:
repns_vector <-1:100
11.4 Estimations
We loop over the 16 scenarios and run the 100 replications in parallel.
The resul_gamsel object is of length 16: each element contains the simulations for a scenario. For each scenario, the elements are a list of length max(repns_vector), i.e., the number of replications. Each replication gives, in a list, the following elements:
scenario: the number of the scenario
repn: the replication number
metrics: the metrics (AUC, Calibration, KL Divergence , etc.) for each model from the grid search, for all boosting iterations.
tb_prop_scores: the estimations of \(\mathbb{P}(q_1 < \hat{s}(\mathbb{x})< q_2)\), for \(q_1 =\{ .1, .2, .3, .4\}\).
scores_hist: the counts on bins defined on estimated scores (on both train and test sets).
11.5 Results
We can now extract some information from the results. Let us begin with the different metrics computed for each of the replications for each scenario.
We can focus on the first replication of each of the scenarios:
repn <-1
We define a function, plot_hist() to plot the distribution of scores also showing some metrics (AUC, ICI and KL divergence) for a particular replication of one scenario. We also define a second function, plot_hist_dgp() to plot the distributions of true probabilities and that of a replication, for multiple scenarios within a DGP.
Ojeda, Francisco M., Max L. Jansen, Alexandre Thiéry, Stefan Blankenberg, Christian Weimar, Matthias Schmid, and Andreas Ziegler. 2023. “Calibrating Machine Learning Approaches for Probability Estimation: A Comprehensive Comparison.”Statistics in Medicine 42 (29): 5451–78. https://doi.org/10.1002/sim.9921.