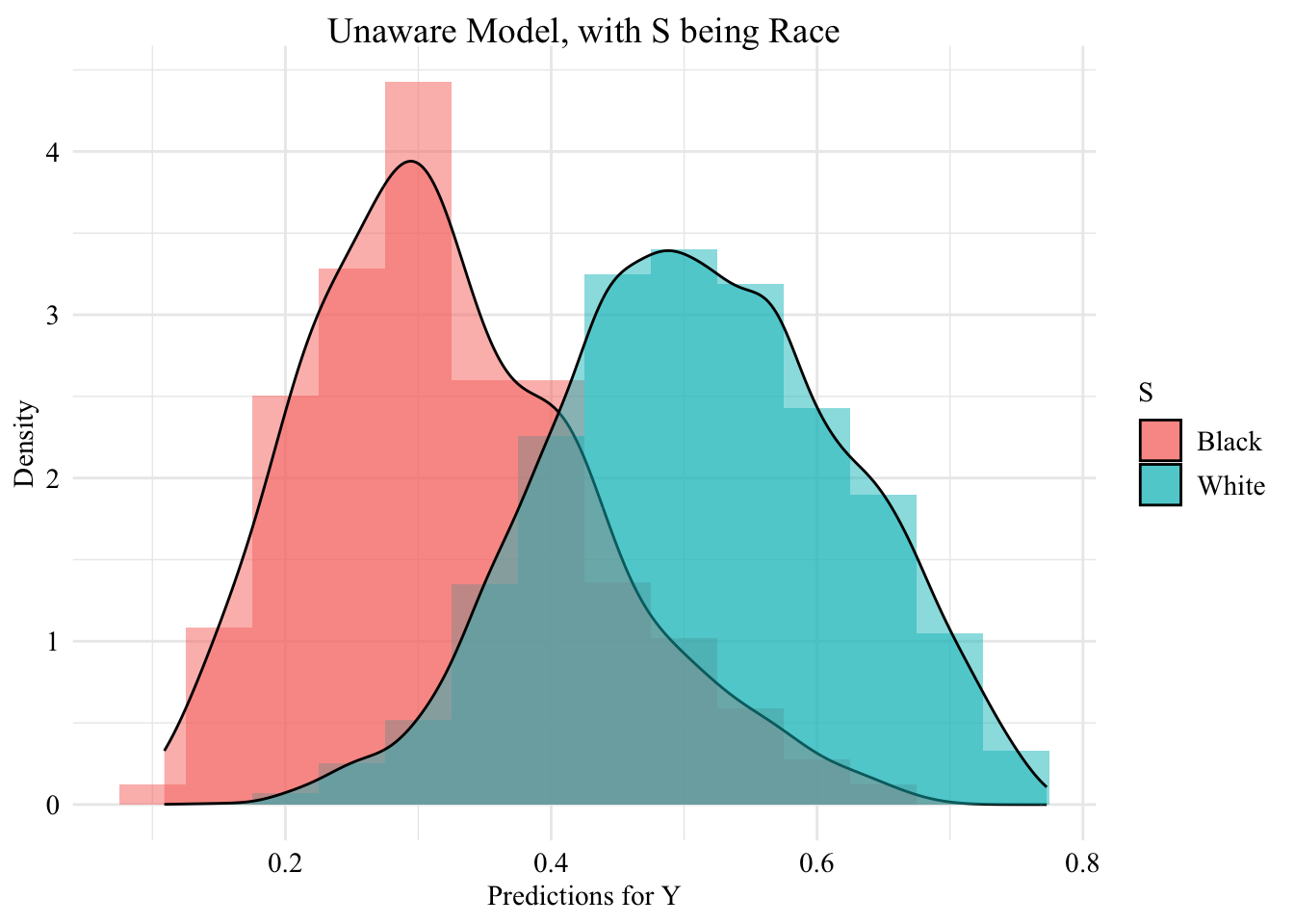
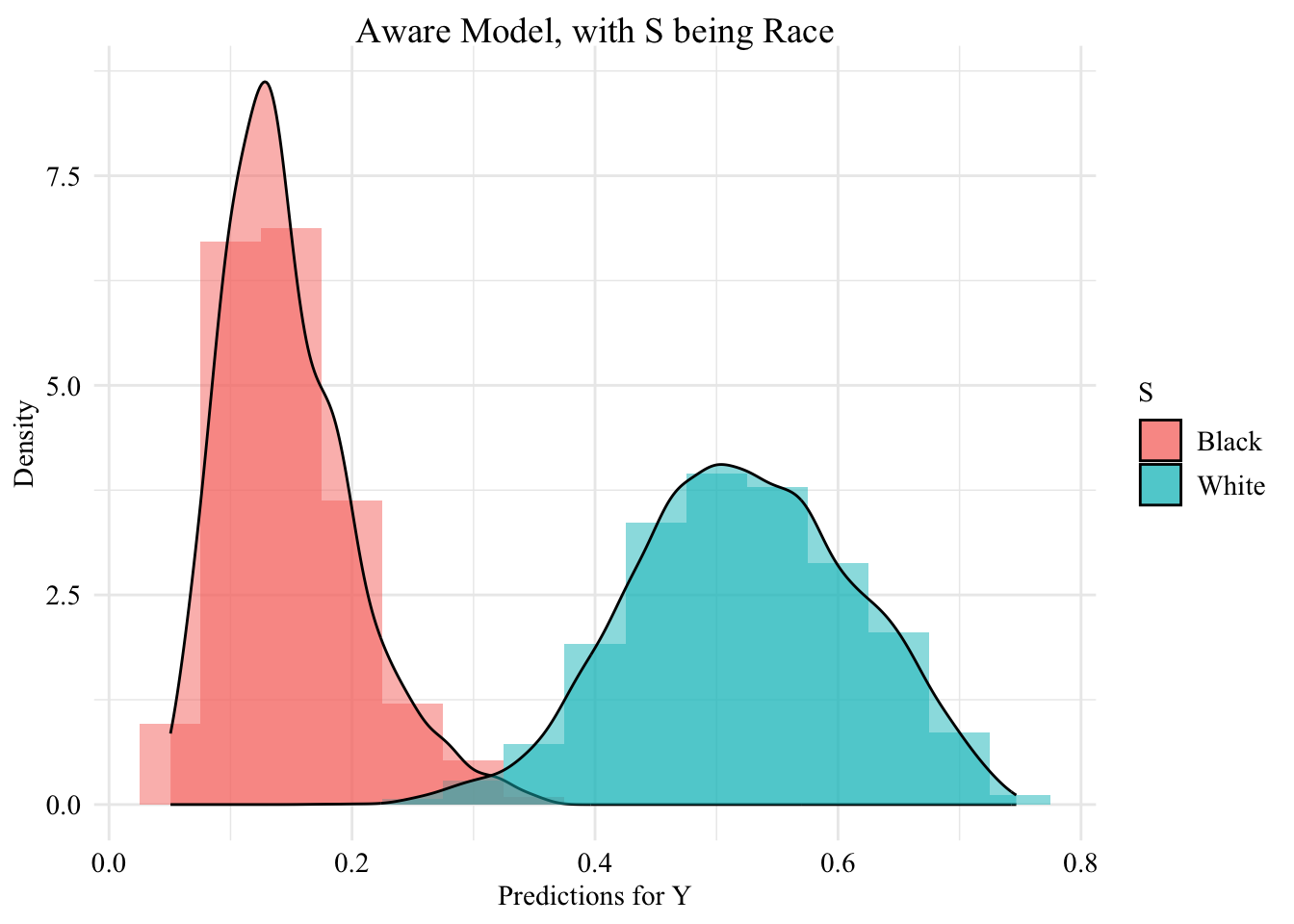
This chapter introduces the scoring classifiers \(m(\cdot)\) trained on the dataset described in Chapter 6. We use logistic regression to predict the outcome \(Y\) based on the covariates \(\boldsymbol{X}\). Two types of models are considered: one that includes the sensitive attribute in the predictive model (aware model) and one that excludes it (unaware model).
Following Kusner et al. (2017), a logistic regression model is trained. To convert \(Y\) into a categorical variable, the median is used as a threshold, in line with Black, Yeom, and Fredrikson (2020). The race, denoted as the sensitive attribute \(S\), has two categories: White and Black. The dataset is divided into training and testing sets. The classifier is first trained and used to compute the necessary quantities for counterfactual inference on the training set. Subsequently, the trained classifier is applied to the test set to make predictions and perform counterfactual analyses. The results of the counterfactuals will also be evaluated on the training set due to the limitation that Optimal Transport in the multivariate case cannot be computed for new samples, unlike the methodologies used in FairAdapt (Plečko, Bennett, and Meinshausen (2021)) and the approach developed in this paper.
unaware logistic regression classifier: model without including the sensitive attribute.
aware logistic regression classifier: model with the sensitive attribute included in the set of features.
The model is trained using the log_reg_train() function defined in our small package.
log_reg_train
function(train_data,
test_data,
s,
y,
type = c("aware", "unaware")) {
if (type == "unaware") {
train_data_ <- train_data |> select(-!!s)
test_data_ <- test_data |> select(-!!s)
} else {
train_data_ <- train_data
test_data_ <- test_data
}
# Train the logistic regression model
form <- paste0(y, "~.")
model <- glm(as.formula(form), data = train_data_, family = binomial)
# Predictions on train and test sets
pred_train <- predict(model, newdata = train_data_, type = "response")
pred_test <- predict(model, newdata = test_data_, type = "response")
list(
model = model,
pred_train = pred_train,
pred_test = pred_test
)
}
<environment: namespace:seqtransfairness>
Let us train the two models. Then, we extract the predicted values on both the train set and the test set.
# Unaware logistic regression classifier (model without S)pred_unaware <-log_reg_train( data_train, data_test, type ="unaware", s ="S", y ="Y")pred_unaware_train <- pred_unaware$pred_trainpred_unaware_test <- pred_unaware$pred_test# Aware logistic regression classifier (model with S)pred_aware <-log_reg_train( data_train, data_test, type ="aware", s ="S", y ="Y")pred_aware_train <- pred_aware$pred_trainpred_aware_test <- pred_aware$pred_test
We create a table for each model, with the sensitive attribute and the predicted value by the model (\(\hat{y}\)), only for observations from the test set.
df_test_unaware <-tibble(S = data_test$S, pred = pred_unaware_test)df_test_aware <-tibble(S = data_test$S, pred = pred_aware_test)
Black, Emily, Samuel Yeom, and Matt Fredrikson. 2020. “Fliptest: Fairness Testing via Optimal Transport.” In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, 111–21.
Kusner, Matt J, Joshua Loftus, Chris Russell, and Ricardo Silva. 2017. “Counterfactual Fairness.” In Advances in Neural Information Processing Systems 30, edited by I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, 4066–76. NIPS.
Plečko, Drago, Nicolas Bennett, and Nicolai Meinshausen. 2021. “Fairadapt: Causal Reasoning for Fair Data Pre-Processing.”arXiv Preprint arXiv:2110.10200.